Documenting a Field: The Life and Afterlife of the ELMCIP Collaborative Research Project and Electronic Literature Knowledge Base

The ELMCIP Electronic Literature Knowledge Base is a large-scale digital humanities database that emerged from a six-nation European research project on electronic literature. The Knowledge Base has since grown to become the most comprehensive open-access contributory database in the field, and is still actively developed. The project director, Scott Rettberg, reflects on the process involved in developing the database and the challenges involved in continuing to document the ever-changing landscape of the field of electronic literature.
The ELMCIP project (Electronic Literature as a Model of Creativity and Innovation in Practice: Developing a Network-Based Creativity Community), which ran from 2010-2013, was one of the most ambitious joint research projects to date in the field of electronic literature (e-lit). The seven-partner, six-nation project resulted in conferences in six countries, a major exhibition, three books, a film, the first digital anthology of European electronic literature, and the ELMCIP Electronic Literature Knowledge Base, a large-scale, open-access research database. This essay will present this multifaceted project within a Creative DH framework. After first presenting the work of the original three-year collaborative research project to establish the context in which the ELMCIP Knowledge Base was originally produced, this essay will discuss the evolution of the database beyond the period in which it was originally funded, how it was adapted to changing circumstances to become an essential component of the electronic literature research ecosystem.
The Knowledge Base is now a decade old. It has developed for seven years beyond the funded project period and has grown into an essential research infrastructure for the field. It has also grown into an essential pedagogical resource for the University of Bergen (UiB) and other institutions of higher learning. Even so, like many DH projects, it exists in a state of precarity, within an institution that, like many others, has only begun to confront the challenges of hosting and preserving DH infrastructure for a long lifespan. During the 2000s and 2010s, many DH projects have been funded and developed on an exploratory basis. Maintaining and continuing to develop a database with needs for both technical and editorial support is not as simple as hosting a website, and requires resources. Universities that are accustomed to investing in and supporting research infrastructure in the hard sciences are grappling with how to treat research infrastructure in the humanities, which were long considered the realm of only thrifty books and chalkboards, rather than technology and engineering. While the cost of maintaining DH research infrastructure is still much lower than, say, the average electron microscope, any institution that is committing to the digital humanities must begin to budget and plan for the long-term development and preservation of research infrastructure.
Background on ELMCIP Collaborative Research Project
Funded by the Humanities in the European Research Area. ELMCIP investigated how creative communities form within a transnational and transcultural context in a globalized and distributed communication environment. ELMCIP’s stated objectives were to:
- Understand how creative communities form and interact through distributed media
- Document and evaluate various models and forces of creative communities in the field of electronic literature
- Examine how electronic literature communities benefit from current educational models and develop pedagogical tools
- Study how electronic literature manifests in conventional cultural contexts and evaluate the effects of distributing and exhibiting e-lit in such contexts.
Within this broader frame, the themes ELMCIP investigated included: the formation of creative and scholarly communities of practice around different factors such as language, region, genre, platform, events, and institutions; different publishing models for electronic literature and the history of electronic literature publishing in Europe; pedagogical models for teaching, researching and institutionalizing electronic literature in different disciplinary contexts and institutional environments; the connections between electronic literature and other modalities of digital arts practice; the applicability of traditional and contemporary literary theory and models of poetics to electronic literature; electronic literature as a performance practice; and models of curating, publishing, and exhibiting electronic literature in diverse contexts including books, online publications, live performance, and gallery exhibitions.
Scholarly outputs included special issues of journals: Performance Research Journal (Fletcher and Allsopp 2013), Primerjalna književnost (Strehovec 2013); and books: Remediating the Social (Biggs 2013), Electronic Literature Communities (Rettberg, Tomaszek and Baldwin 2015), Electronic Literature as a Model of Creativity and Innovation in Practice: A Report from the HERA Joint Research Project (Rettberg and Baldwin, 2013) and numerous peer-reviewed articles in scholarly journals. The ELMCIP Anthology of European Electronic Literature published eighteen works of electronic literature in different European languages on USB drives (for archiving and Creative Commons-licensed sharing) and on an accessible website, including pedagogical materials.
Among other results, ELMCIP led to increased cooperation between the European and North American research communities in the field. During 2013, the last year of the ELMCIP project, the first European edition of the Electronic Literature Organization conference and exhibition took place in Paris, and the conference has subsequently shifted to an annual schedule that alternates between Europe and North America with subsequent editions taking place in Milwaukee, Bergen, Victoria, Porto, Montréal, Cork, and (in a virtual pandemic-era iteration) Orlando. ELMCIP also contributed to the development of an international Consortium of Electronic Literature (CELL) developing databases and archives of electronic literature around the world.
The ELMCIP Electronic Literature Knowledge Base was likely the most enduring material contribution of the project, because it did not come to a conclusion when the funding ran out. By the end of the ELMCIP project the Knowledge Base had become the most extensive online research resource in the international field. The Knowledge Base has grown from a narrower focus on representing European electronic literature and critical discourse – which grew almost immediately to encompass American electronic literature in its scope – to a broader international focus. The database will be the main focus of this chapter. But it is important to understand that the database emerged from a particular research context and field-building agenda and is part of a larger ecosystem of research activities.
Framing a digital humanities project as embedded and development-oriented research
The full title of the ELMCIP project was “Developing a Network-Based Creative Community: Electronic Literature as a Model of Creativity and Innovation in Practice.” A core aspect of the project was thus from the beginning not only to study a community that already existed but also to develop international collaboration and research infrastructure that would better help to give shape to a creative community and a shared knowledge base. In particular, ELMCIP was intended to help ignite collaboration between European research communities with a concentrated period of activities in six European countries and the creation of a research infrastructure of enduring value to the field. Building upon Drucker and McGann, in her contribution to this ebr gathering, Alex Saum-Pascual (2020) posits creative making as critical thinking. The vision of DH embraced by ELMCIP was creative community making as critical thinking.
The premise of the ELMCIP project was that creativity does not emerge in isolation but is instead the result of distributed cognition that occurs over time within a community. This is particularly the case in a field such as electronic literature where creative artists for example are typically working on platforms developed by others, or reworking bits of code that might have first been developed by other programmers, and where collaborative co-creation is just as common as individual authorship. Our investigation foregrounded the assumption that creative practices have been profoundly altered by the digital turn, and that the global network of the Internet enabled new forms of networked creative practice. We put forth the international electronic literature community as an exemplar that might enable better understanding of broader cultural shifts in network-based creative communities. We found among other things that while practices in electronic literature grew out of established traditions in specific countries and language communities (for example a vibrant kinetic and combinatory scene in Portugal sprang out of an established tradition in visual poetry), as the World Wide Web was widely adopted around the turn of the century, creative practices and venues for electronic literature shifted to a much more international focus. Collaborations across borders, and across language barriers, have become commonplace. This model of creativity as a networked, distributed activity informed our development of the Knowledge Base.
Developing a conceptual model of a field
The Knowledge Base is intended to document electronic literature as a dynamic field of practice, one whose cultural import becomes more comprehensible when the activities of authors, scholars, publications, performances, and exhibitions can be related to each other, in multiple configurations. We designed the Knowledge Base as a platform in which this complex web of relationships can be made visible and available for analysis. Researchers can begin to trace the activities generated or enhanced by a work as it circulates among different reading communities. When a record of a critical article is documented in the Knowledge Base, all the creative works it references are noted, and cross-references then automatically appear on the record for the work itself. Similarly, cross-references are made to every other type of record it touches—for example when a work by a particular author is entered, a reference automatically appears on that author’s page, likewise for works published by a publisher. The Knowledge Base makes perceptible interactions between human and nonhuman actors, and documents the diverse range of artistic, scholarly, and pedagogical practices in the field of electronic literature.
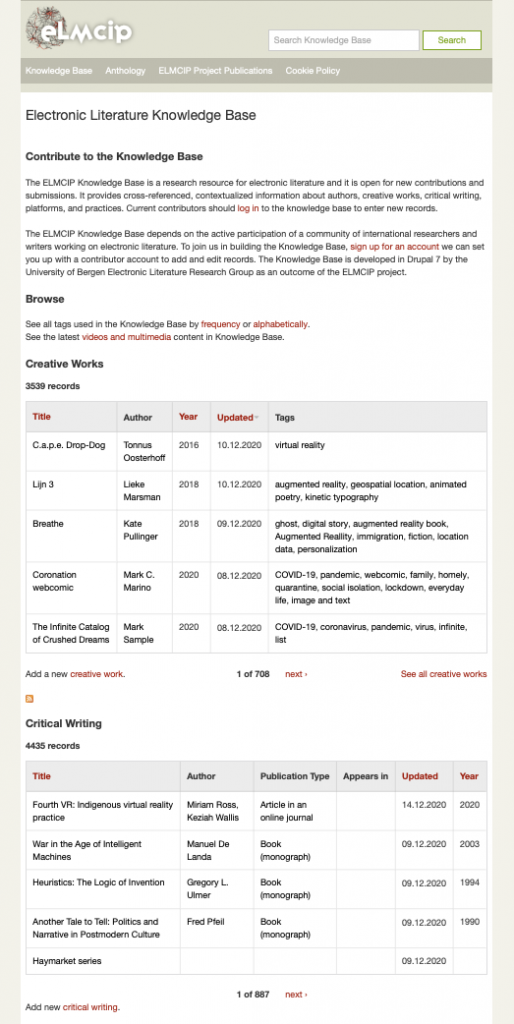
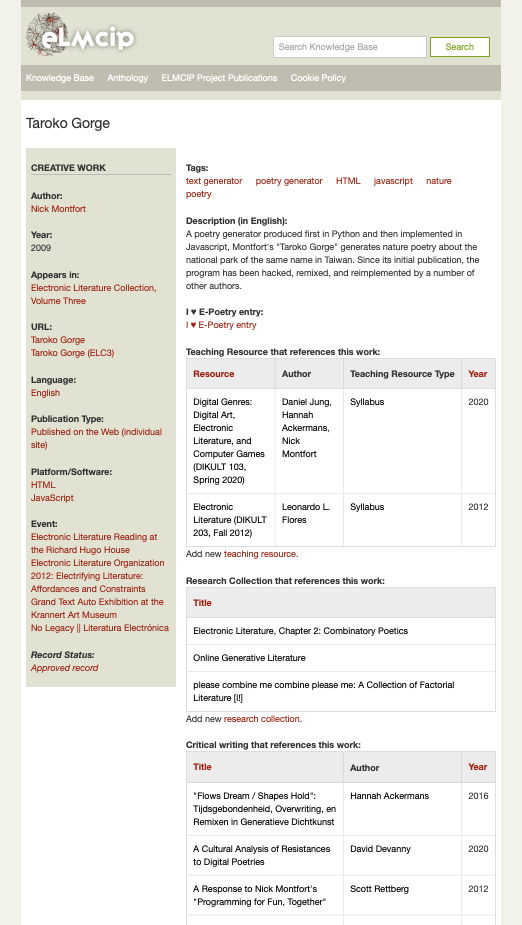
The Knowledge Base is an open access and contributory database. The majority of the information in the database can be accessed by anyone with an Internet connection, without logging in. The main constituency of the Knowledge Base is researchers and scholars who study literary production native to digital environments. Serving as both a platform for research and a site for self-reflexive community formation, the Knowledge Base is a participatory online database. We create contributor accounts on request for any researcher or writer working in the field. While a team working mainly at the University of Bergen’s Electronic Literature Research Group (BEL) has been responsible for the development of the platform itself and a great deal of the content in the database, contributors to the Knowledge Base also include many writers and researchers who are practicing artists and scholars in the field, contributing remotely from many different parts of the world. The writers who create, critique, perform, and respond to works of e-lit help shape the digital literary field. By documenting actants and activities they deem significant, we can present the Knowledge Base as a collectively authored, networked research environment.
The development of the Knowledge Base involved a good deal of “scope creep” — at first we intended only to document the scholarship and creative works that were being specifically addressed in publications related to the ELMCIP project, but as we developed a team (including researchers, creative writers, librarians, and a developer) and began to specify the different types of objects and actors that should be documented in the database, we realized that we were developing a conceptual model of the field as a whole. We then decided to open up the scope in order to document as much of that field as we could. The project shifted from one with a relatively narrow focus to a broader project of epistemology and the development of a “field model” which while specific to electronic literature, could also be applied to other fields of research and creation. 1 A distinctive aspect of the Knowledge Base is that it tracks relations between different types of objects and actors and makes those visible and pliable to researchers.
As we developed the platform, we addressed a number of specific challenges:
Challenge 1: Build institutional infrastructure to secure memory and develop context
An enduring research infrastructure is required to develop electronic literature as a field of writing practice, rather than existing as a potentially infinite series of ad hoc writing experiments too often identified with ephemeral technical innovations derived from the use of particular platforms or software. While novelty—ranging from fiction made in early hypertext systems to kinetic poetry produced in Flash to writing in three-dimensional immersive CAVE environments to story generation systems—has been a hallmark of this creative field of practice, a field cannot be built on novelty alone. From the standpoint of researchers and teachers, memory is more important than novelty, as true novelty is not possible without understanding the past. If we cannot understand present experiments and innovations in the context of those that have come before, we have very little context for teaching, or for new innovation. And because of the contingencies of digital media, memory has posed some very specific problems. Researchers in the field of electronic literature deal with artifacts that exist in media and technical platforms that have shorter lifespans than printed books. The majority of digital literary artifacts that electronic literature researchers encounter are both literary works and computer programs. Because of the pace of technological change, platforms very quickly become obsolete, so over time works of electronic literature become increasingly difficult to access and study. Further, traditional institutions of literary culture such as libraries, publishers, and university curriculum committees have struggled with practices of documenting, disseminating, evaluating, and preserving these types of literary artifacts, which are materially distinct from printed literary artifacts, offering complex archiving challenges.
In many established disciplines, research infrastructure has been in place so long that they might seem to be transparent. Everything from research databases to academic presses to scholarly and creative journals and conferences at which to present current work have long been in place for print-based literary studies. In most arts and humanities disciplines, young artists, academics, and researchers can be initiated into an already-existing infrastructure, which, even if it is changing, remains stable enough that most pedagogic energy can be devoted to passing along relatively established methodologies. Authors and scholars of electronic literature, however, have had to address the fact that the field’s institutions, organizations, and methodologies did not have an a priori state: they had to first be invented and then attended to, so that innovative work could continue to bear fruit. The Electronic Literature Knowledge Base is both a manifestation of this field-building process—providing a better means to document and preserve creative and critical practices—and a platform through which the developing infrastructure of the field can be made visible and accessible.
Challenge 2: Map the context to understand and facilitate a literary ecology
There is a need for tools to both provide access to creative works and scholarship and to provide a clear context for understanding the relationship between creative and critical work. Compared to other fields of humanities research, electronic literature has developed in an atmosphere of close symbiosis between critical and creative practice. If one were to examine the institutional structures of contemporary print creative writing and contemporary literary studies, one would likely discover that writers and critics operate in their own milieus, with the “writer’s workshop” set off in a separate wing of the university from literary criticism. As an emergent field, electronic literature has more often found the critics and the writers present in the same rooms: presenting creative work and critical work at the same conferences, publishing work in similar venues, and participating in the same discourse networks. Another important contextual difference is that e-lit has been interdisciplinary from the start: so, it is not merely a matter of writers and critics working in close quarters, but that people of diverse backgrounds have also been engaged: in visual and conceptual arts, communications and design, programming and computer science. Further, the publication venues in the evolving field diverge in substantial ways from traditional modes of literary publication. A work of electronic literature might have been published on a CD-ROM or online journal, venues that might map roughly onto print publishing practices, but it might also be exhibited in a museum or art gallery or presented as a live performance. By documenting and mapping out not only creative works and critical writing but also the diversity of cultural venues—and most importantly by making the connections between them visible—we can provide new avenues of understanding creative, critical, and cultural practices as existing within a dynamic ecosystem, a literary ecology.
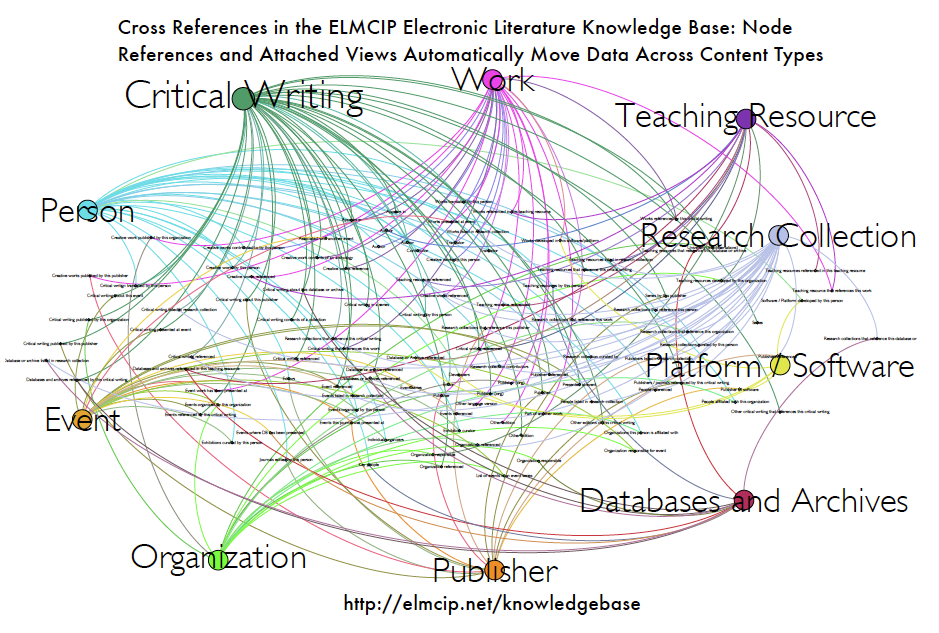
Challenge 3: Identify networks of relations to better understand literary community
One model of understanding literature and literary culture is as a series of works produced by authors—a term that can be carried over from print to include individual expressions within and across media, arts and institutional platforms. Such works are produced by variously talented individuals working in isolation and can be best experienced in an immersive, contemplative mode. The database on the contrary expresses the community emphasis of the project overall: the idea that both literary community and the literary artifact itself can be understood as networks of relations. A conception of a work of electronic literature as a network can be derived from the formal and material qualities of many of the works themselves: a hypertext novel built of links and nodes, offering multilinearity and branching paths in place of narrative arc; a kinetic Flash poem built of timeline, sprites, and assets rather than stanzas and lines; a poetry generator that is an algorithmic structure that assembles poetry from arrays of possible verse. In studying these types of works, we understand them as networks of relations between different parts, producing contingent literary experiences on the computer and network. The literary ecology that results in the creative practices of electronic literature can be understood as a network of networks, encompassing human and machine intelligence, social practices and affiliations, software platforms, ad hoc alliances, and formalized institutions. Core to the conception of the Knowledge Base is the idea that those networks should be acknowledged, made visible, documented, and accessible for study. This is not just an abstract theoretical concept but one which, for instance, has consequences for bibliography and institutional placement of electronic literature as a field. One goal of the ELMCIP project was to bring database methods and an archival sensibility to types of artifacts and practices that are not often documented in a bibliographic fashion.
We have expanded the original scope of the coverage of the Knowledge Base. Having done the work of defining the type of metadata we wanted to collect for the objects and actors we were documenting, it seemed that rather than simply archiving the work of the fixed-term project and the outputs of the European research team collaborating on the project for a three-year period, it would instead make sense to document as much of the field as possible on an ongoing base. The project thus became more expansive and more open-ended. If we were doing a database focused on literature produced during a fixed period, or the corpus of a single author, or even of a regional historical movement, the scope would have been much more definable. But instead, the Knowledge Base tracks a field that is itself continuing to develop. The scope of the database is thus such that it will always be incomplete. It is following a moving target, a field that is continuously springing new tentacles in the present and in the past, as knowledge of historical work is recovered.
The risks and affordances of an open knowledge community
The Knowledge Base is itself based on an open, contributory architecture. It is structurally similar to a Wiki in the sense that contributors must have an account to add or edit records, but once they do, they can edit and enhance any existing record. The Bergen Electronic Literature Research Group and students working in courses taught at the University of Bergen have been responsible for a great deal of the editing and development of the database, but its coverage and future growth depends on a participatory knowledge community. There is, of course, a good deal of risk entailed in depending on such a community to develop content for a research database. When we first began to develop the Knowledge Base, people would often express concern about contributors willfully vandalizing the database or adding incorrect information for malicious reasons. This has not proven to be a significant issue. For the most part, when people come to edit records, they do so in order to improve factual information and to extend the usefulness of the records. Perhaps unsurprisingly, a greater problem has been in motivating the electronic literature community to join in editing records. Every year we work with our students and BEL to add information, update, and work additions and edits to the Knowledge Base. But the students we work with often start with little to no knowledge of the field, and no one editing the Knowledge Base is doing so on a full-time basis. The quality of the information and of the coverage of the database improves greatly when the writers and researchers working in the field take the time to document their own work and to improve the documentation of works that they care about.
In contrast to some of the other databases in the field, such as the Electronic Literature Directory, the Knowledge Base focuses less on readings and more on capturing core metadata and the relationships between works and critical writing about them. In his essay in this gathering, Joseph Tabbi (2020) notes that the two databases differ essentially in that they “can stand roughly for the close and distant, fragmentary and relational readings.” While the ELD includes carefully articulated encyclopedia-style short essays about a comparatively small group of works (around 300 or so), the ELMCIP Knowledge Base largely leaves subjective description, literary analysis, and interpretation to the critics. While some work descriptions and folksonomic tagging of works is done by contributors and editors of the KB, our focus is on simply documenting as much of the field of practice as we are able to. Because we document critical writing as well as creative work and because of the cross-referencing system, records for works of criticism about each work are made available on the record for the work. So detailed readings of particular works are made visible and accessible from the KB, although for the most part they are external to the database itself. Thus, in comparison to the ELD, the Knowledge Base is driven more by discovery than by edification. The UQAM-based French language NT2 database represents an approach somewhere in between that of the ELD and the Knowledge Base, in that it has a wide scope and for the most part presents core metadata, but it also includes a selection of more detailed examinations of specific works. As Tabbi notes in the conclusion to his essay, the distinct approaches of the ELD and the Knowledge Base complement each other, and perhaps in the near future we can merge the two databases into one shared research infrastructure that includes the strengths of both, with the extensive metadata capture and cross-referencing of the Knowledge Base joined with the more detailed descriptive records of the ELD. Such a unification seems feasible if we are able to find the human and technical resources necessary to do so.
The Knowledge Base has grown over time in a branching tree structure. The essential mechanism through which information is gathered is through relations between objects and actors within different content types: creative works, critical writing, authors, platform/software, teaching resources, publishers and journals, organizations, events, databases and archives, and research collections. The majority of the metadata is not entered in plain text fields but in autocomplete fields which search for the node of the entity entered in the relevant field (for example author, publisher, creative or critical works referenced) from those that have already been entered in the database. If the field cannot autocomplete, the person editing the record will need to create a new record for the entity that is missing. This results in a great deal of incomplete information in the database – if a contributor is to create a record for a creative work that was published in a new online journal, they might have to stop and create new records for both the author and the publisher. If the contributor is pressed for time, they would likely only create a “stub” record with the most basic information. While in an ideal world, everyone would completely document all of the entities referenced in a new record, in the real world, contributors don’t often have time to do so. However, this apparent weakness is also in some ways a strength of the project. Each incomplete record is a kind of bud waiting for another editor or contributor to come and grow it. When we work with students in our digital humanities course at UiB, we often start with incomplete records and discover how each of them serves as a kind of path down a rabbit hole – a lead to follow to discover new works and articles and parts of the web of connections that have not yet been fully explored.
Records come into the database in a variety of different ways: primarily through the contributions of researchers in the field, but also in a more concentrated way through the course “Digital Humanities in Practice” at the University of Bergen. In that course and occasionally in our research group one of our main methods for discovering and developing records for works is by trying to document all of the electronic literature referenced in a book. For example, we held a “Funkhouser Friday” on the occasion of the publication of Chris Funkhouser’s book New Directions in Digital Poetry where we tried to document all of the e-lit works referenced in the book. One researcher in our group, Andrés Rodriguez, is currently doing the same with Alex Saum-Pascual’s #Postweb! Crear con la máquina y en la red. We do the same with major collections and anthologies of electronic literature and with journals that publish e-lit. We are always running behind the production of the field and will never catch up – it is the nature of the enterprise. Moving from this sort of collective project, the students develop their own research questions and paper topics and develop further database records as they do so. But one class at one university cannot do it alone. Other teachers, such as Alex Saum, Davin Heckman, Dene Grigar, Jonathan Baillehache and others have also fruitfully integrated both the use and editing of the Knowledge Base into their courses. 2 This type of pedagogical work, that integrates the study of electronic literature with its documentation in the Knowledge Base, is one of the ways that we can work together as an intellectual community to sustain and improve our research infrastructure. And it should be noted that while producing records in the Knowledge Base is a documentation activity, it is also a very rewarding research activity. In our course, students discover that the works cited page to a monograph or the reference list of an article is not merely an ornamental decoration: it is a kind of treasure map. And rather than simply reading about works of electronic literature, in developing records for the database, students actually take the opportunity to read them. I have found that students take pride in the fact that their work is not simply transmitted from student to teacher for evaluation, but is rather published on the web, and immediately becomes a resource for other researchers to use. It matters in a different way and serves as a steppingstone into the research discourse community of electronic literature.
One consequence of the broad scope and international focus of the ELMCIP Knowledge Base, and its contributory nature, is that its coverage will always be partial and will always be biased by the scope of the research of individual researchers. The field has been growing rapidly and expansively in the past decade, and it is simply impossible for a small group of people working part-time on the project, on the most part on a volunteer basis or as an aspect of their studies, to keep up with all the activity. There are significant gaps of coverage in the database, some of which have been written about critically. For example, in his essay in this ebr gathering, Ryan Ikeda notes that when he searches the ELMCIP database for terms like “blackness,” “race,” and “racialization” he comes up with zero search results (Ikeda 2020). Ikeda did this in the context of searching for one particular work that he expected to find in the database – Mendi and Keith Obadike’s art installation “Blackness for Sale” – a conceptual work in the form of an eBay ad in which Obadike commodified his own blackness. Actually, a search for “race” does in fact turn up some results, but only five, and “Blackness for Sale” was not there. Ikeda argues that this absence is one piece of evidence of “white supremacy” in the institutions of e-lit. While I think Ikeda perhaps goes a step too far in labelling the field of electronic literature thus, the broader lacuna is one worth considering in the context of the database, how it is developed, and how it represents one of the ways we can work together to address diversity in the field. In the case of “Blackness for Sale” most researchers have described the work as digital art. Ikeda’s essay was the first time I saw “Blackness for Sale” referred to as second-generation e-lit – though as I search Google now, I see that in 2017 Brian Kim Stefans included a reference to it in his “Electronic Literature” chapter of the Cambridge Core American Literature in Transition 2000-2010, and it makes perfect sense to me that it should be represented in the Knowledge Base as e-lit. Neither the work nor Stefan’s chapter are yet documented there. This is precisely the type of moment at which our collective endeavor to document, shape and improve the field can and should be activated. While I can’t tell any researcher how to spend their time, I argue that if you find yourself using the ELMCIP Knowledge Base as a researcher to find sources, you should also be contributing to it as a researcher to help others find sources. The moment at which you search for a work that you consider to be essential to your research in electronic literature, and find it to be absent, the moment that you are irritated or amazed by that lack, is the precise moment at which you might want to stop and create a stub record. It is not above or below any e-lit researcher’s pay grade to do so.
The Knowledge Base is not built by some monolithic hegemonic blob—it is built by an intellectual community. And if you are researching or writing electronic literature, you are part of that community, and you are welcome to join us in the work of documenting and reshaping the field over time. Electronic literature’s research infrastructure is not something to be merely excavated, it is something to be continuously rebuilt. The database is not only there to be searched, and it is not only there to be read: it is there to be written, by all of us. Beyond that, of course, the field needs to expand its reach into diverse and underrepresented communities, both to identify works that are not yet visible to the institutional e-lit community, and to help inspire authors in diverse communities to create new work. I take it as a positive sign that researchers in a variety of international communities, in part inspired by the Knowledge Base, are developing new databases focused on specific language communities and cultures. For example, Reham Hosny has done work to aggregate Arabic language e-lit, the Lit(e)Lat group is publishing an anthology of electronic literature produced by Latin American authors, digital poet and ELO Fellow Yohanna Joseph Waliya is beginning to develop a database of African electronic literature, and the dra.ft group is organizing activities to spur e-lit creation in India. There is still a long way to go, but progress is being made.
We need to recruit early career scholars whose scouting work and close readings of electronic literature are recognized by peers and accrediting agencies. Like many forms of DH labor, this is work that should is not often enough recognized and rewarded as a vital service of the field and an important form of research. One example of an attempt to do so that ELO now has in place is a cohort of ELO Fellows affiliated with databases not just in Europe, Scandinavia, Australia and the USA but (as of 2020) India and Africa. And just as important, is the normalization of e-lit courses in university classrooms that ask students to draft entries on selected, assigned works.
Ikeda’s critique of the Knowledge Base is an indicator that we are sorely in need of more input from electronic literature authors and researchers working in critical race studies, both to bring in documentation of works and criticism of e-lit that addresses race and diversity, and to tag records in the database that already address these matters. The Knowledge Base has “controlled vocabularies” for core bibliographic information, but not for themes and content descriptions. In this case, we use a folksonomic “tagging” system that is idiosyncratic precisely because it is open – each individual contributor tags the records they contribute or develop using an uncontrolled vocabulary. In my course, I encourage students to go on “tagging missions” to identify and make visible specific themes and research concerns. This is something that we need more of, and from a more diverse group of contributors. There is a question, of course, as to whether or not we should have instead used a fixed taxonomy for these thematic concerns, as at this point, the tagging system is in no way systematic. But limiting and declaring a fixed taxonomy that is itself subjective would also delimit the paths of entry into the works. For example, the NT2 database has a fixed taxonomy based on the material and technical properties of works: this is useful, but it also establishes a way of reading the database (and therefore the work it documents).
As Louis Althusser asserted in a different context, every cultural apparatus is ideological (Althusser 1971), and the apparatus of databases are no exception. During the process of designing a database, there are some decisions that we make consciously – for example the decision to make the database open-access and contributory – that reflect particular ideological standpoints. But during the process of designing the database and during the years of operating it, we have seen that even small decisions about what fields to include and what to leave out, how to gather and share information, what functionalities to able and disable, are all in some sense political decisions, in the sense that a database is a model of the field that it represents, which recursively impacts that field in the process of modeling it. As Berry and Fagerjord note in their discussion of the ELMCIP Knowledge Base in Digital Humanities, “Inescapably, any computer model will be reductionist, so while models make calculations and computer-based research possible, they also leave out important details” (Berry and Fagerjord 2017, 63). These decisions, essentially, about what to leave in and what to leave out, can and will be read and interpreted ideologically from different points of view. In her contribution to this gathering, Hannah Ackermans proposes a framework for database criticism, and makes a compelling argument that we “take seriously the use of the database as acts of reading and interpretation.” Ackermans argues that in evaluating databases, “the objectives and means of a database need to be identified and the reviewer has to think along with them in reviewing the database.” (Ackermans 2020). That is to say that just as we strive to read works of literature in the period and cultural contexts in which they were produced, we need to consider databases from the perspective of their aims, constraints, and institutional contexts.
As we developed models of the field as a whole and identified objects and actors in this field, we became aware of how important and how complex single facets of documenting a text or an organization or a person could be. For example, under “person” there is a field where we can mark gender, which has the options of “male, female, or other.” The subject of whether to include this field to begin with was a matter of some debate when we first designed the database, and initially it was not included. At this point there is not really a standardized way of marking either sex or gender in scholarly databases, and my initial inclination was that it was not entirely relevant to the type of bibliographic-style documentation we were doing in the Knowledge Base to gather this information. But other researchers working with our group pointed out the fact that for doing certain types of research – for example if one wanted to do a study of representation of women in electronic literature publications over time – that information would be invaluable. Some years after we added the field, however, I received a furious response from an author who had changed their gender identity in the years since their author record had been added to the database. The author perceived the outdated recording of gender in this context as a kind of “dead naming” and a personal violation. While of course we immediately fixed the record, it gave rise to a spirited debate about the status of the gender field in the database itself. While some authors actively edit their own records, for the most part, authors’ names and brief biographical information are gathered from other publicly available sources. It would be functionally beyond the means of our resources to track down every person who is named as an author in the database to ask them to maintain their own author record. Yet gender information even at the most basic level is quite personal. In the end, we decided that gender information will not be displayed on the “public” version of the person record, though we did not delete the gender information we had previously gathered from the database itself, and authors can still define that information in the field. But our general policy now is that we will not indicate an author’s gender unless they specifically declare that information themselves while editing the record. This is an imperfect solution: value is lost for researchers, and for representation of gender diversity in the database. But we need to weigh that research and representation value against the risk of doing harm to people by misrepresenting something as personal as their gender, and we need to do so within the constraints of the resources available to us. In this case we elide in favor of the principle of trying to “first, do no harm.”
Ackermans also notes that “perpetuating bias in data collection and quantitative research is inevitable” and we need to “consider how the data is captured, which implications are made about the research potential of the data and how big of a discrepancy there is between those two.” In his essay “Digital Poetry and Critical Discourse: A Network of Self-References?” Álvaro Seiça demonstrated some of these biases, for example that because certain authors have been more active than others in documenting their own work and criticism, there may be imbalance in how much of their work is represented vs. that of other authors. As he notes, this is partly because currently all the records in the database are entered by humans rather than harvested by an automatic survey of references (Seiça 2016). And because documenting the references within a monograph or article is quite labor-intensive, many of the records in the database are incomplete in this regard. Nevertheless, the Knowledge Base is the most extensive record of citations available to the field. It will never be complete, but it does provide a substantial representation of the relationship between critical writing and creative work in the field.
Database development as constructive experimental research
The development of the Knowledge Base was not a purely linear process, but an essentially experimental one. Many of the types of objects and artifacts documented in the Knowledge Base did not have standardized documentation models that would correspond for example to library cataloging standards: How do we create a record for a live performance of avatars in a virtual world such as Second Life? How do we account for a chatbot? An explorative process of invention was thus involved even in the core work of developing the knowledge model.3 Further, specific uses and functionalities were developed only after the database had been in development for a good deal of time. For example, it did not occur to us to implement pedagogical applications and teaching resources within the database until we realized that we had documented a significant body of creative works and criticism – why not build a functionality for developing course materials right inside the database itself? This is but one example of many cases where the process of making the database revealed new uses and new avenues of research.
The ability to develop research collections focused on specific topics, regions, languages, and other specific concerns is one of the most important research functionalities we developed in ELMCIP – one that allows researchers to develop a kind of mini-database inside of the database. A research collection can gather together any type of record in the database along with descriptive or analytical text. This is used by researchers who want to develop and provide a more focused presentation of a subset of materials. We have also tried to use this to expand the range and diversity of the database’s coverage. On several occasions, PhD researchers and short-term postdoc visitors have developed collections that document works in specific languages and cultures: some examples include the Portuguese collection (curated by Álvaro Seiça), the Russian collection (curated by Natalia Fedorova), and the Brazilian collection (curated by Luciana Gattass). Researchers also develop collections based on specific research themes – for example the “Collection of E-Lit Works Affected by The Lability of the Device” assembled by Patricia Tomaszek, or a new collection of works and critical writing responding the COVID-19 pandemic that I am curating with Anna Nacher and Søren Pold as an aspect of a DARIAH-funded research project we are developing on the topic.
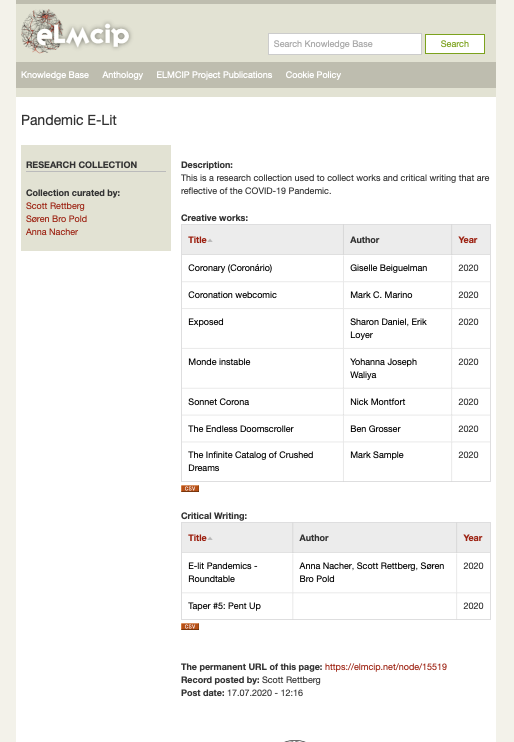
By collectively building a large dataset of documentation of the field of electronic literature and the relations between objects and actors, the ELMCIP Knowledge Base also led us to new forms of DH research: data-mining and visualizing patterns of citation, co-authorship, and other relationships, by extracting datasets to address specific research questions and by creating visualizations that illustrate results. For example, I wrote a paper that asked: “Can we identify an emerging canon of electronic literature based on all of the citations of creative works from critical writing documented in the database?” (Rettberg 2014) while Jill Walker Rettberg (J. Rettberg 2013) considered trends and themes in the field by analyzing all of the 60 dissertations available in the database at that point. Both Jill Walker Rettberg and I are revisiting our original essays now to see how the patterns of citation have changed in more recent years – as the database has more than doubled in size since the time of our original analysis. Álvaro Seiça used visualizations to consider how we could analyze communities of authorship and citation in the history of digital poetry. This type of distant reading activity would not be possible for electronic literature without the large body of documentation and relational data the Knowledge Base contains. Students in our courses also regularly develop these kinds of data visualization-based analysis to consider everything from platforms of electronic literature to what genres have been represented in the different awards for creative work in the field. These projects also strengthen the database as they are developed as we always try to develop the data set of whatever topic is concerned by developing and editing related records before harvesting the information from the database.
Long-term sustainability, data sharing, and the afterlife
ELMCIP was initially a well-funded three-year (2010-2013) collaborative research project. The Knowledge Base was initially conceptualized as an output from the project, but we did not realize at the start how important it would become to the international field of research. Like many DH projects, we have faced significant challenges in sustaining, maintaining, and continuing to develop the project. At the same time as the Knowledge Base is now a core activity of our research group, it has been a challenge to maintain institutional support, and considerable time and energy that would be better spent developing the content of the database has had to go into a seemingly endless quest for support to maintain a basic level of funding for maintenance and development of the platform itself. Beyond simply hosting and editing the active online research platform, the Knowledge Base requires technical support, which can be expensive and difficult for traditional humanities faculties to account for and provide within normal academic funding structures. A strategy for long-term sustainability of DH research infrastructure calls for cooperation at many different levels. In the case of the ELMCIP Knowledge Base, we need to work at the level of the international research community, national research infrastructures, the university library, and our own faculty to find a solution for long-term sustainability. At the University of Bergen, we are going through a slow process of developing a support structure in which the University Library takes on the long-term mission of supporting and maintaining DH research projects and infrastructures that are first developed by researchers and research projects. The University centrally and the Humanities faculty recently decided that DH should be a priority of the University Library and have directed resources there to accomplish that. But this sort of switch is not easily accomplished overnight, as each individual project requires specific technical support competencies.
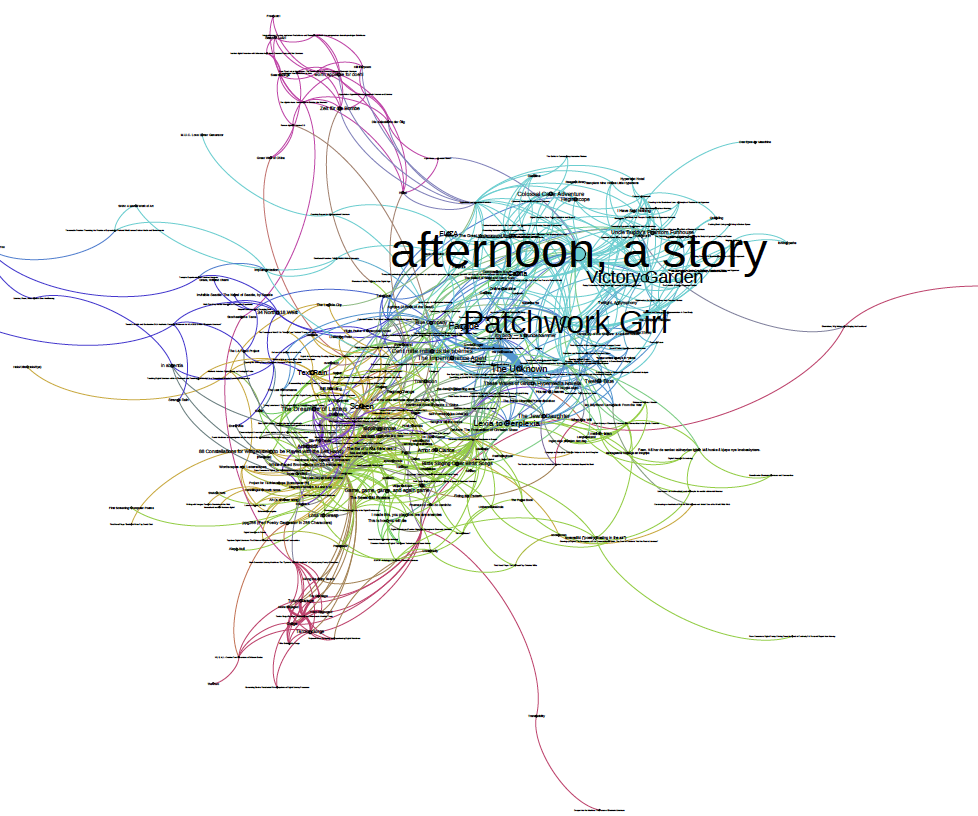
I mention the “afterlife” of the ELMCIP project in the title of this essay and by this, of course, I mean the Knowledge Base has lived beyond the ELMICP project to become a cornerstone of research in the field. But over the course of the decade of developing the Knowledge Base, I have realized that we also need to think about the afterlife of the database itself. When planning any DH project or research infrastructure, it is wise to plan for a regenerative end state. That is to say that the project itself (any project) will end. Whatever platform a database is developed in will eventually become obsolete. Funding and support for projects will wax and wane and evaporate. As curators of knowledge essential to preserving the memory and discourse upon which a field is built, we need to plan to assure that information that is recorded, and knowledge that is produced, is neither dependent on any single technological platform, nor upon the whims of particular institutional funders, nor upon the energies or employment of any particular individual. Although I anticipate that the Knowledge Base will continue to have a long and productive lifespan in something resembling its current form, we also need a backup plan to assure that the knowledge it encompasses survives. In this respect, the Consortium on Electronic Literature, organized by the Electronic Literature Organization, is an important piece of the puzzle. The CELL consortium includes 11 different organizations, research labs, and research centers, most of which host some kind of database or archive related to electronic literature. The consortium serves two important purposes: one is to make creative works and critical resources findable across all of the databases in the consortium via a common search engine. The search engine is currently being implemented by BEL and will be reactivated in early 2021. This will allow us to find all related records for a given search term in all of the databases at one time – for example, a search for “Patchwork Girl” would deliver the records for Shelley Jackson’s hypertext fiction not only from the Knowledge Base but also the ELO’s Electronic Literature Directory and the NT2 database. Perhaps even more important from a long-term preservation standpoint is that all of the CELL members have agreed that should one of the databases or archives lose its funding or otherwise reach its end of life, we will commit to migrating its data to another platform within the consortium.
Over the course of the past two decades, the field of electronic literature has out of necessity developed its own research infrastructure. The Electronic Literature Organization has been central to the establishment of the field: a structured human network of researchers and writers around the world who have developed conferences, readings, and online events at which to gather and share research in progress and creative work. The ELO gradually further developed online research infrastructure to fill gaps in the field: the Electronic Literature Collections – a series of online anthologies of electronic literature that gather and preserve works and provide researchers a set of common references, the Electronic Literature Directory, a research database that documents and provides detailed descriptions of a group of works, and most recently the Electronic Literature Archives, a repository of archives of journals that have published e-lit, individual e-lit authors archives, and other archival collections of materials related to e-lit. Journals that regularly publish works or criticism of electronic literature, such as ebr, The New River, and Hyperrhiz are another aspect of this infrastructure, providing venues for the distribution of new work and scholarship. Extensive research databases such as ELMCIP, NT2 and a growing group of others have provided us with a common set of references and metadata upon which to not only build anew but also remember the work of the field in a way that preserves it and makes it teachable. These research infrastructures are in many ways more tenuous than those that support research in more traditional fields, and they should not be understood as fixed in the same way as research infrastructures for more established fields (for example the MLA International Bibliography). That tenuousness is both a curse and blessing. While the DH research infrastructure of electronic literature is sometimes a bit messy and kind of wobbly, something of a patchwork assemblage, it has also served as an experimental space that has allowed innovative approaches from a variety of different angles and perspectives. And, as I described in the first essay I wrote on the subject of electronic literature as DH, “Communitizing Electronic Literature,” (2009) all these projects are the products of an electronic literature community dedicated to developing a culture that will support and sustain its development. At the same time as the Knowledge Base is dedicated to documenting a field, the field itself must bring in further activity if the database is to continue to develop and thrive. If you are a researcher of electronic literature, or an author of electronic literature, sign up for an account and log in and document your work and the work that you care about. If you are a teacher working with electronic literature, consider teaching with the Knowledge Base. Help us to edit and refine and document and reshape the field over time: it belongs to all of us.
Works Cited
Ackermans, Hannah. “Appealing to Your Better Judgement: A Call for Database Criticism”, Electronic Book Review, July 5, 2020. http://electronicbookreview.com/essay/appealing-to-your-better-judgement-a-call-for-database-criticism/
Althusser, Louis. “Ideology and Ideological State Apparatuses (Notes towards an Investigation).” Lenin and Philosophy and Other Essays. Monthly Review Press, 1971.
Berry, David and Anders Fagerjord. Digital Humanities. Polity, 2017.
Biggs, Simon, ed. Remediating the Social. ELMCIP, 2012. https://elmcip.net/sites/default/files/media/criticalwriting/attachments/remediatingthesocialfull.pdf
Fletcher, Jerome and Ric Allsopp. “On Writing and Performance.” Special issue. Performance Research Journal 18.5, 2013.
Funkhouser, Chris. New Directions in Digital Poetry. Continuum, 2012.
Ikeda, Ryan. “Excavating Logics of White Supremacy in Electronic Literature: Antiracism as Infrastructural Critique.” Electronic Book Review, Jan 10, 2021. http://electronicbookreview.com/essay/excavating-logics-of-white-supremacy-in-electronic-literature-antiracism-as-infrastructural-critique
Obidake, Mendi + Keith. “Blackness for Sale.” 2001. http://archive.rhizome.org/anthology/blacknetart/ebay.html
Rettberg, Jill Walker. “Visualising Networks of Electronic Literature: Dissertations and the Creative Works They Cite.” Electronic Book Review, July 6, 2014. http://electronicbookreview.com/essay/visualising-networks-of-electronic-literature-dissertations-and-the-creative-works-they-cite/
Rettberg, Scott. “An Emerging Canon? A Preliminary Analysis of All References to Creative Works in Critical Writing Documented in the ELMCIP Electronic Literature Knowledge Base.” June 01, 2014. http://electronicbookreview.com/essay/an-emerging-canon-a-preliminary-analysis-of-all-references-to-creative-works-in-critical-writing-documented-in-the-elmcip-electronic-literature-knowledge-base/
Rettberg, Scott. “Communitizing Electronic Literature.” DHQ: Digital Humanities Quarterly 2009 3.2. http://www.digitalhumanities.org/dhq/vol/3/2/000046/000046.html
Rettberg, Scott and Sandy Baldwin, eds. Electronic Literature as a Model of Creativity and Innovation in Practice: A Report from the HERA Joint Research Project. The Center for Literary Computing and ELMCIP, 2014. https://elmcip.net/sites/default/files/media/criticalwriting/attachments/rettbergbaldwinelmcip0.pdf
Rettberg, Scott, Patricia Tomaszek, and Sandy Baldwin, eds. Electronic Literature Communities. The Center for Literary Computing and ELMCIP, 2015. https://elmcip.net/sites/default/files/media/criticalwriting/attachments/rettbergelectronicliteraturecommunities.pdf
Rettberg, Scott and Eric Rasmussen. “The ELMCIP Knowledge Base.” in Electronic Literature as a Model of Creativity and Innovation in Practice: A Report from the HERA Joint Research Project. 293-340.
Saum-Pascual, Alex. “Digital Creativity as Critical Material Thinking: The Disruptive Potential of Electronic Literature.” August 2, 2020. http://electronicbookreview.com/essay/digital-creativity-as-critical-material-thinking-the-disruptive-potential-of-electronic-literature/
Saum-Pascual, Alex. #Postweb!: crear con la máquina y en la red. Iberoamericana-Vervuert, 2018.
Seiça, Álvaro. “Digital Poetry and Critical Discourse: A Network of Self-References?” MATLIT 4.1(2016): 95-123. http://dx.doi.org/10.14195/2182-88304-16
Stefans, Brian Kim. “Electronic Literature.” American Literature in Transition, 2000-2010. Rachel Greenwald Smith, ed. Cambridge University Press, 2017. 193-210.
Strehovec, Janez. “Electronic Literature and the New Media Art.” Thematic Section of Primerjalna književnost 36.1, 2013.
Tabbi, Joseph. “Something there badly not wrong: the life and death of literary form in databases.” Electronic Book Review 07/05/2020. http://electronicbookreview.com/essay/something-there-badly-not-wrong-the-life-and-death-of-literary-form-in-databases/ Portions of this essay were adapted from Rettberg, Scott and Eric Rasmussen. “The ELMCIP Knowledge Base” in Electronic Literature as a Model of Creativity and Innovation in Practice: A Report from the HERA Joint Research Project (2014).
Footnotes
-
A different kind of modelling of relationships between authors and text was explored by the RoSE project, directed by Alan Liu and the Transliteracies Project, which focused explicitly on relationships between communities of authors and the texts they produced, visualizing extensive creative communities over time as social networks: https://liu.english.ucsb.edu/rose-research-oriented-social-environment/ ↩
-
It is interesting to note that the courses in which people have integrated editing the database include both digital humanities courses and foreign language courses: for example, Baillehache’s course was focused on French literature in the digital age, and Saum’s is a Spanish Transmedia literature course. ↩
-
For a more detailed description of the content types and fields used to describe them, see Rettberg and Rasmussen, 2013. ↩
Cite this essay
Rettberg, Scott. "Documenting a Field: The Life and Afterlife of the ELMCIP Collaborative Research Project and Electronic Literature Knowledge Base" electronic book review, 3 January 2021, https://doi.org/10.7273/kfmq-7b83