To Hide a Leaf: Reading-machine for a Book of Sand

Working with a custom-coded, automated-art-system of their own devising, Australian digital artists Karen Ann Donnachie and Andy Simionato have now archived a literary corpus for future study in what they have called The Library of Nonhuman Books. Yet it remains uncertain whether human scholars will visit Donnachie's and Simoniato's virtual library. Seeing as how "there are no human ‘typewriters’ now, how can we be sure there will still be human ‘readers’ in the future?"
In this essay, we will describe how and why the reading-machine was ideated, what the reading-machine does, as well as definitions of the terms we have adopted within the research.
We will begin by outlining how the reading-machine uses computer vision and Optical Character Recognition (OCR) in order to identify the text on any open book placed under its dual-cameras, we will then describe how the system leverages Machine Learning (ML) and Natural Language Processing (NLP) to uncover brief ‘poetic’ combinations of words on the page, which it preserves, while erasing all other words. Finally, we will describe how the reading-machine automatically searches for an illustration from the Google Image Archive to ‘illuminate’ the page according to the meanings of the remaining words.
Once every page in the book has been read, interpreted, and illuminated, the system automatically publishes the results using an Internet printing service, and the resulting volume is then added to The Library of Nonhuman Books. In this essay, we are primarily focusing on the design and functions of the reading-machine, and we will address the books it creates, and the implications of the literary and aesthetic outcomes these embody, more closely on another occasion.
1. Significance of the title
The title of To hide a Leaf: Reading-machine for a Book of Sand contains two references to Jorge Luis Borges’ parable “El libro de arena” (1975). Perhaps the most explicit refers to the mythical “book of sand” itself, described in Borges’ story as a volume which continuously recombines its words and images at every reading, potentially consisting of an infinitude of pages. The same Borges story is also the source of the words “to hide a leaf” which were algorithmically identified as ‘words of interest’ by an early prototype of the reading-machine when presented pages from the English translation of Borges’ collection of stories. The complete sentence printed in the edition of Borges’ which contains the words is: “Somewhere I recalled reading that the best place to hide a leaf is in a forest,” as the narrator finally rids himself of the book by placing it among other books in the basement of a library (91). The significance of this passage for our work lies in the project’s attempt to reveal the ‘latent verse’ which also hides in plain sight, like a leaf in a forest, or even a ‘leaf in a book.’ Together our interest in the combination of these ideas, the book as a combinatorial machine with the potential to regenerate at every reading, and our capacity to reveal new meanings otherwise hidden in plain sight on the page, led to our attempt to build a reading-machine which could calculate a series of seemingly infinite combinations of words that, until that moment, have been readable, but not consciously perceived, by the reader.
2. Design of the machine

We began developing the conceptual and physical design of the reading-machine after seeing photographs of the scanning devices used by Google Inc. during its (more or less successful) attempts at mass-digitizing all the world’s physical books. Google’s ambitious project of transferring every physical book through scanning and Optical Character Recognition into digital texts generated some legal and ethical controversies around its use of literature. For these reasons detailed photographs of Google’s scanning methods and the machinery used in its scanning centers were relatively difficult to access. After some guess-work we created the earliest proof-of-concept model of our reading-machine which consisted of a modified library book-scanner that used a regular Pi-camera connected to a Raspberry-Pi controller running the custom-coded python scripts that would eventually become the algorithm we describe later in this essay.
We quickly departed from the use of this relatively bulky book-scanner and began experimenting with a much smaller (and easier to transport) dual-camera device where each camera can be independently moved to focus on either the left or right page of a two-page spread of the book (see Image 01). This system permitted the use of two less expensive lower-resolution cameras (640 x 480px) instead of the higher pixel-dimensions needed in a single-lens system (2592 x 1944px), having the added benefit of avoiding the need to adjust the resulting image for page-deformation – as the pages of a book naturally curve outward from the spine when it is laid open, this often causes poorer character recognition. We discovered later that the lower pixel dimensions also decreased the time required for processing the images, which in turn permitted a more efficient video frame-rate and this encouraged us to add a monitor with a live-feed of the reading when situating the work for exhibition. In practice, this reading-machine is far simpler to engineer than any of our other drawing and computer vision machines, and similar results could be generated from the custom-scripted micro-controller if it were connected to 2 small generic digital-cameras mounted in parallel and placed over an open book. The novelty of the reading-machine lies more in its algorithm than in its physical design.
3. The algorithm
In the broadest terms, our reading-machine generates and publishes a new book by ‘reading’ any existing book. The algorithm that drives this automated-art-system can be described in three broad phases which can be loosely referred to with the following terms: Reading, Interpreting and Illuminating. Although we remain wary of anthropomorphizing the machine when adopting these analogies of human behavior, they remain useful in this limited context. Besides, just as the word ‘computer’ once signified a human role before the invention of the micro-chip, why shouldn’t we imagine that the etymology of ‘reader’ not follow a similar path? As there are no human ‘typewriters’ now, how can we be sure there will still be human ‘readers’ in the future?
Returning to our promise of presenting the principle formulae which comprise these three phases of the algorithm, here is a more detailed explanation of each:
Phase 1: Reading (Computer Vision and OCR)
In this initial phase of the reading-machine’s processes, the individual words on the double-pages are identified and mapped to their geometric (XY cartesian) coordinates.
The process begins by using the Tesseract Open Source Computer Vision driven optical character recognition (OCR) performed on the book placed within the frame of the reading machine’s cameras. The text is tokenized into words and the words are stored in an array with their coordinates, and forms the multiset ‘terms.’

Phase 2: Erasure (Machine Learning and NLP)
The second phase of the algorithm reveals a subset of words from the body of words already printed on the pages of the physical book, with a view to generate meanings from these newly revealed words.
The algorithm determines ‘words of interest’ which are flagged to remain, and the remainder which are flagged to be removed, through a process of digital erasure of the image of the page. The results of the process can be observed in real-time through a live-video feed (as they were in xCoAx2019) and stored for post-processing to later appear in the form of a new printed publication. How and why specific subsets of the existing words on the page are considered ‘of interest’ instead of others became an important question within the project, and we should dedicate some time to discussing how we reached the selection criteria used in the working-prototype presented.
The algorithm is (currently) tasked with finding a ‘goodness of fit’ of a 5/7/5 syllable structured poem (sometimes referred to as a Haikù poem originating from Japanese literature) latent within the finite set of words detected on each double page.
The algorithm semantically parses the set terms, filters for English ‘stopwords,’ which NLP classifies as generic, but necessary, parts-of-speech (for example pronouns, particles, conjunctions and prepositions) and ranks the words by degree of ‘salience.’ Salience in this context is measured using a calculation of inverse document frequency (idf), a comparative measurement of term [t] frequency [f] within the double page (local corpus) vis-a-vis frequency in our ‘global’ NLTK corpus (a combination of Project Gutenberg, Carnegie Mellon Univeristy (CMU) and Brown University corpora), to find words that are peculiar to this text (Pedrone). The most salient words instantiate the ‘keep’ subset.
An inverse document frequency can be illustrated as such (Huang):
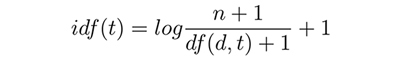
The algorithm proceeds to randomly select a single (or pair) of highly salient words to feature in the poem. A series of potential 5/7/5 syllable combination of words, as they appeared in the original word-order, and which include the chosen word, are tested by brute force predictive forward iteration. The syllabication is determined using NLP (CMU) pronunciation dictionaries for U.S. English. Additionally, as the poem forms, its ‘grammar’ is checked against parts-of-speech dictionaries to inform the word choice. If the poem falls below the threshold of ‘plausible’ grammar, there is an opportunity—where possible within the rules of syllable count and convenience of location— to re-include previously excluded ‘stop’ words. If the poem still fails the threshold of plausibility, it is discarded, and the algorithm begins composing/searching the poem again.
Once a match is found that resolves to the completion of the poem within the double page spread, any unused words are removed from the keep set and are slated for erasure. The resulting poem is de-tokenized to sentence level and added to the local corpus, thereby influencing the subsequent outcomes of the following pages, within the current reading. The erasure itself is driven by Open CV image reconstruction function which is based on the “Fast Marching Method” by Alexandru Telea, and the desired effect is that the resulting image attempts to maintain the original ‘matter’ of the paper (implied texture and color).
 Image 04: (above) “deep down men try there / he’s large naked she’s even / while facing anything” [Resulting poem from E.L. James’ Fifty Shades of Grey]
Image 04: (above) “deep down men try there / he’s large naked she’s even / while facing anything” [Resulting poem from E.L. James’ Fifty Shades of Grey]
(below) “how parties popcorn / jukebox bathrooms depressed / shrug, yeah? all” [Resulting poem from Bret Easton Ellis’ The Rules of Attraction]
Currently, this editing/redacting phase of the reading-machine algorithm offers significant potential for experimenting combinations of calculation, chance and choice. Although the current iteration of the algorithm generates a sufficiently nuanced interplay of what is admittedly deterministic rule-based Haikù-like poetry generation, we are committed to exploring further opportunities for translating the reading-machine’s outcomes through other criteria. For example, we have initiated work on exploring the potential for a version of the algorithm which generates ‘concrete poetry’ from the pages of existing books as well as introducing a new capacity for performance of the found ‘poetry’ through a synthetic voice.
Phase 3: Illuminating
In the final phase of reading, the machine determines one word from its previously selected subset of words on the double-page, with which it performs a search through the Google Image Archives in order to illustrate the spread. We refer to this process as ‘illumination’ in an attempt to accentuate the linking of the algorithmic processes of our reading-machine to the medieval practice of book-construction, from the hand-made books of the 13th century, through incunabula and the early print period of Western Europe. We can return to why we are linking the pre- and post-literate book-making practices in another moment. For now, we will focus on the more technical questions of how these processes function.
This ‘illumination’ function of the algorithm uses the initial featured ‘salient’ word(s) to perform a semantically driven Google Image search for an accompanying line drawing to illuminate the double page. Given the possibility for synonyms of salient themes to recur throughout a text (local corpus) and thus return similar or identical results, the algorithm logs the images retrieved, and will choose the next best match if the specific image has previously been used in the current reading of the book.
Currently the system specifically searches within the ‘line art’ category when it utilizes the Google Image Archive for this phase, as results from this category are more consistent with the aesthetics of illustrations from medieval scripts and are more suited to monochromatic printing processes which we will discuss shortly. However, we have also experimented with broadening the search base to the entirety of Google’s Image Archives, allowing for inclusion of photographic images for example, with outcomes that encourage further exploration of a diversity of archives and typologies of image.
4. Iterations
The first working-prototype of the reading-machine was capable of generating a live-video feed of any page or spread from a physical book with many of the printed words appearing ‘erased’ to reveal new meanings.
We considered this iteration technically successful in generating images of the book’s pages that appeared sufficiently authentic. Interestingly, these images (or video-feed of images) maintained all the book’s paratextual elements; page numbers, marginalia, paper color, and other phenomenological elements to suggest to the viewer they were experiencing the earlier ‘reading’ the original printed book. We had sufficiently created the illusion of perceiving new meanings that had always been there on the page, yet were hidden from the reader. At this stage in our research we observed a distinct affect of experiencing the new (erased) page when it was printed out on paper, and this led us to experiment with adding a final step which consisted in publishing the results of everything ‘read’ by the machine as a new book. This step was relatively straightforward to implement, and was resolved through procedural python scripting which converted all pages to bitmap images of 1bit (black) according to threshold (required for one color Black printing), followed by imposition of pages to the required specifications (dimensions, color space, resolution) before finally saving as print-ready PDF files (most often one each for cover and text) ready for digital delivery to printer.
5. More questions than answers
At first glance, these more recently appropriated books present themselves as identical in many ways to the original books they are derived from, yet they have been radically transformed in the meanings they generate. This unease opened new questions within the project. Although the (remaining) words in these versions generated new, unexpected meanings, they remained exactly on the page where they had been printed in the original book. Our reading-machine had operated only on the relationships between words on the page, inducing a tension between the familiar and the alien.
Once we realized that the project was generating more questions than we could answer in the short term we began keeping the resulting A.I.-designed books in an archive for further study. This (growing) archive is now called The Library of Nonhuman Books, and at the time of writing it contains roughly 100 volumes based on around 40 original titles (see www.atomicactivity.com). Furthermore, to encourage discussion, and reinforce our own intentions for how our system can be used, we include bibliographical end-matter on the last page of each book generated. It is significant that this paragraph, which includes the original book’s bibliographic details, a web URL to reach the authors of the algorithm, and other details like the UTC timestamp of reading, is also generated and added without human intervention.
Each reading of any physical book by the machine, can produce a multitude of ‘illuminated scripts’, each one revealing new meanings that were always there in the original, but have remained hidden until that moment.
In a time where books are being transformed into clouds of words, this project helps them find new bodies that lie somewhere between the human and nonhuman. A publishing experiment for our post-literate society, which increasingly defers its reading to nonhuman counterparts.
Works Cited
Borges, Jorge Luis. El libro de Arena. [The Book of Sand]. Norman Thomas di Giovanni [Trans.]. Buenos Aires: Emecé Editores, 1975 ; 1977 [Eng trans].
Huang, Luling. “Measuring Similarity Between Texts in Python.” https://sites.temple.edu/tudsc/2017/03/30/measuring-similarity-between-texts-in-python/ Accessed 05 July 2019
Perone, Christian. S. (October 3, 2011b). “Machine learning :: Text feature extraction (tf-idf) – Part II.” http://blog.christianperone.com/2011/10/machine-learning-text-feature-extraction-tf-idf-part-ii/ Accessed 05 July 2019
Acknowledgments
We acknowledge and appreciate the contributions of Open Source Libraries and software: Python, Tesseract OCR, Natural Language Toolkit (NLTK), Pillow, OpenCV, Tkinter; Natural Language Corpora: Carnegie Mellon University, Project Gutenberg, Brown; Token table assistance by Emma Baillie; xCoaX2019 and ELO2019 for the opportunity to present this research for the first time, and to all those with whom we shared conversations around the work. This paper references machine-readings of the following original editions: Shades of Grey by E L James Vintage Books, USA, 2012; The Rules of Attraction by Bret Easton Ellis, Penguin Books, UK, 1988; The Psychology of Perception by M.D. Vernon, Penguin Books, UK 1962. All media materials in this essay courtesy Karen ann Donnachie and Andy Simionato (Donnachie, Simionato & Sons), 2019.
Cite this article
Donnachie, Karen Ann and Andy Simionato. "To Hide a Leaf: Reading-machine for a Book of Sand" electronic book review, 3 May 2020, https://doi.org/10.7273/chg4-cx05