Critical Code Studies Conference - Week Two Discussion
In the second installment of a six-week discussion, contributors search for examples of Critical Code Studies "in the wild." Instead of asking how code can be read critically, they examine how code is already being created and disputed by lawyers, programmers, and the general public.
In the second installment of a six-week discussion, contributors search for examples of Critical Code Studies “in the wild.” Instead of asking how code can be read critically, they examine how code is already being created and disputed by lawyers, programmers, and the general public.
Editor’s Note:
In the second installment of the discussion that took place in the summer of 2010, Jeremy Douglass leads the Critical Code Studies Working Group in exploring the practical challenges and constraints of reading code critically, with an emphasis on real-world examples. An introduction and overview for this week by Mark Marino and Max Feinstein is available here. -Ed Finn
Reading Reading Code
________________________________________
How should we read code?
In crafting my contribution to our shared conversation, this question has been my starting point, both because and despite the fact that it is (in many ways) simple, obvious, and the wrong question. First, I’ll spend a short time framing one aspect of the enterprise of Critical Code Studies as I see it, then draw out some of the implications for concrete ways in which code becomes an object of criticism and then circulates in a critical discourse. How do operations like citation, paraphrase, and especially quotation function in code criticism, and how do we constitute and circulate those primary sources that secondary readings then rely upon? Next, I would like to perform a substitution:
"How should we read code?" ->
"How do we read code?"
“How do we read code?” is the more generative and productive question in many respects. It brings into focus our own diverse code reading practices, and asks us to explore the complexity that actually underlies a “two cultures” stereotype of ur-programmer and ur-critic literacies. It also invites us to go further: “How does everyone already read code?” suggests we look to the myriad ways in which code criticism already exists “in the wild,” far outside disciplinary categories.
Let me begin at the beginning.
Code, but Critically
Week 1 briefly situated Critical Code Studies in relation to the recent emergence of a set of overlapping interdisciplinary areas of inquiry, including Software Studies, Platform Studies, Hardware Studies and, of course, Critical Code Studies. But what is our more general situation?
Why “Critical Code Studies”, as opposed to “Code Studies”? Is it just a marker of difference, distinguishing an open field of new interdisciplinary exploration, where “Code Studies” could be confused with the established paradigms of software engineering and computer science?
Yet the term “critical” suggests its own established paradigm. Critical * Studies is a popular phrasal template (or perhaps snowclone) in academia, particularly in the creation of new cultural studies subfields. So for example in the case of Critical Disability Studies or Critical Terrorism Studies, the critic (who apparently does not merely study, but does so critically) is distinguished from the presumed inner-standing point of a default domain professional: the medical expert on disability, the government agent on terrorism, the programmer on code and so forth. Read in this light, “Critical Code Studies” suggests a great mapping of one culture of knowledge onto another: some practices of hermeneutic textual commentary, perhaps taken directly from the humanities or arts, and then mapped onto the domain of programming in software engineering and computer science.
Code for Two Cultures?
Of course, my invoking the metaphor of “mapping” hugely oversimplifies the CCS project and its participants - and also does so in a way that implies a kind of territorial violence. Is code a territory at all? I don’t choose to believe so, but I’m drawing out the idea because it seems to be implied in several debates that already recur regularly around CCS, many framed in terms of cultures of disciplinary power:
- If code is territory, does the philosophy of mathematics hold dominion over it, while the huddled hermeneutic masses yearn to breathe free? Conversely, does the imperialist culture of continental philosophers seek to invade and colonize code’s virgin soil, displacing its native culture?
- What counts as a productive relationship to code, or to reading in general? What constitutes a dangerous relationship? Who is qualified to be productive? …and why must all you people from [$OpposingSide] insist on devaluing my modes of literacy, especially when you haven’t even tried to understand them?
In my own background, I’m reminded in many ways of the recent emergence of the “Narratology vs. Ludology” debates in Game Studies. These debates were sometimes productive conversations about the key terms of a new endeavor. Yet, at their most heated, they tended to obscure the diverse and subtle positions of participants. The problem with a “two cultures” frame is that the insertion of a “versus” hides the rich interdisciplinarity of a community by posing a false choice: which of two sides will emerge victorious and thereafter be allowed to speak?
Literacy -> Literacies
My original draft preparation for this assembly traced connecting lines from scholarly publishing culture towards software engineering culture, undertaking a set of heuristic or syllogistic explorations to imagine what a productive code criticism culture might look like, moving from the big issues down to the nuts-and-bolts level of the code snippet:
- Reference: What are the paratextual and intertextual conventions or archival infrastructures needed to support code availability that might keep a critical work comprehensible over time? What are the contextual and intertextual demands of that fact that code meaning is increasingly situated within complex and rapidly evolving platform ecosystems, whether across the operating system or the network? For example, is a complete emulation image of an appropriate configured Windows machine circa 2001 necessary to truly understand the AnnaKournikova worm? Is a complete copy of the Google PageRank algorithm (or indeed Google’s data cloud) necessary to understand a search engine artwork which makes use of Google APIs?
- Citation: How and what do we cite when we use code (as opposed to or in addition to software) as a primary source in a publication? What are the issues specific to code about versions and their production and reception that should be reflected in citation style?
- Quotation: What are the basic principles of significance and selection? What are useful strategies and conventions for excerpting (e.g. ellipses, explicit substitution, editorial comment, etc.)? What are the forms of paraphrase, through pseudocode, documentation, description, or otherwise? Where are they appropriate and how should they be signaled? Is Text : Quotation :: Code : Snippet? How?
- Illustration: When does illustration become necessary, in response to code environment paradigms (e.g. patch programming or weird languages) or affordances (e.g. syntax highlighting, folding, search, or visualization)? What are the forms of illustration useful for code, whether screenshots, video clip, executable applets, emulation snapshot etc.?
This a priori exploration can of course be performed in the opposite direction as well, a posteriori. We could start with the conventions of speaking about code that already circulate in global discourse that both is code and is about code - the history and culture of the documentation, diffs, snippets, pseudocode, proofs, and paraphrase that already make up part of the evolving literacies of programming textbooks, computer science articles, and code forums. Just as humanists are not inventing the idea of reading code critically, scholars are not inventing the idea of a textual apparatus around code - but everyone has much they could gain from and contribute to understanding code.
The act of imagining multiple reading communities and concerns in relationship to code is beneficial to all. Insisting on the power and importance of practical fluency in programming does not disenfranchise the cultural critic. Similarly, evocative readings of keywords and their poetics or cultural overdeterminations do not displace the authority of the pragmatic programmer. Finally, there is not a spectrum of two literacies - there are myriad literacies that are not mutually exclusive.
How I’ve Read Code
After a week of this workshop, I’ve come to the conclusion that Mark Marino’s admonition to show-not-tell has been incredibly productive. Big meditations on our models and frameworks for code citation aren’t the spirit of the day - the thing to spur on the conversation is a little less taxonomy and a little more bestiary.
In ending on a specific note, one strategy I considered was to follow the AnnaKournikova example from Week 1, taking a code snippet that has appeared in my own previous critical writing and presenting it for group discussion. This would probably have been either:
- Andrew Plotkin’s interactive fiction Shade, the Inform 6 source code of which is discussed in some detail in my dissertation Command Lines and in a chapter of Harrigan and Noah Wardrip-Fruin’s Second Person. This is in many ways my favorite personal code reading, as it tries to explore the aesthetic meaning of the code from the point of view of the user, the interpreter, and the programmer in terms of the history of both a single play session and evolution of the programming language.
- Basic Screen Effects by Emily Short, an Inform 7 library. I briefly highlighted this in my ""#include Genre” pecha kucha presentation at SoftWhere 2008, in which I sketched out how libraries and header files function in source code, the way that they are inherited, and how they can become vectors for unintended aesthetic effects. Short’s library code here is particularly interesting in that she has been deeply involved in the evolution of the language specification, compiler, IDE, documentation, demo code, and award-winning works that make up the total code ecosystem of Inform.
- Beep.path, the “hello world” program of the PATH Interpreter (and, with quine-like simultaneity, the logo as well). PATH is an esoteric / weird language that I’ve presented on at Electronic Literature Organization and Digital Humanities talks that discussed the rhetorics of patch-based and visual flow programming. In “What Counts as Code to Criticize? Interpreting flow control and natural language programming” [video] at the Software / Code Studies panel of Digital Humanities 2009, I tried to begin with our default assumptions about what code is (e.g. imperative programming languages such as C) and explore the implications of code criticism within other paradigms. Part of this grew out of my earlier thinking on visual code at Electronic Literature Organization 2008: “Flowchart Art: Programming Literary Flow.”
Who Reads Code?
My challenge to the workshop for this week is to find concrete examples of actual code reading that enrich our idea of who reads code, and how - particularly examples that refine, complicate, or move beyond “two cultures” stereotypes of the code programmer with a mind of winter and the code poet with a heart too easily made glad. Code has many real and ideal readers, with many goals. One of these (and an important one) is the ideal programmer. Another is the ideal machine - a compiler, VM, or scripting engine. In one particular story about these ideal readers, the ideal programmer is purely motivated by functionalism, while the ideal machine engages in an interpretive procedure untroubled by ambiguity. Rather than detail this ideal, I propose a dose of the real. Real code readers also include:
- mathematicians reading for beauty
- craftsman reading for elegance
- customers reading to make a purchase decision
- managers reading for quarterly job evaluations
- hackers reading for exploits
- tricksters reading for obfuscations
- amateurs and hobbyists and students
- …making their first web page
- …copying some other script kiddy
- …or just trying to learn to think differently
- lawyers and expert witnesses
- …looking for a DUI acquittal in a breathalyzer
- …impugning the code or security of a voting machine in a recount
- …trying to define an intellectual property violation in an open source OS
- easter-egg hunters
- …collecting trivia from code
- …harvesting data and media assets from code
- …indexing business contacts from code
- …participating in ARGs and viral marketing campaigns in code
Make no mistake - people (and not just professional programmers or techno-critics or industry gurus) already read code critically. They argue about whether the code is functional, but also whether the code is virtuous or deceitful, conscientious or negligent, egalitarian or discriminatory. People debate whether a single piece of code represents either a global warming hoax conspiracy or the messy work of legitimate science. They treat code archives as business-lead opportunities, and post online shopping-cart exploit code as a way of fighting the man. They claim that code legibility is akin to a fundamental human right - or they claim that the act of changing code itself is akin to a mortal sin against the almighty creator. People bring audiences together around performances that dip in and out of reading code. These discourses don’t represent an illiterate or vulgar culture at the periphery of core programming culture, either - they are the very heart of literate programming. Groklaw began as way for programmers and legal experts to combine expertise in the history of UNIX source code with a partisan intervention in a contentious lawsuit - an expertise crowdsourcing in response to the massive exhibition of code as evidence. “Forks” are often code civil wars, in which a code writing community splits along lines of functionality, but also aesthetics, personality, and working culture.
What can we learn from these readings? What techniques and perspectives can we offer that would best serve both ourselves and our home disciplines, and also these communities?
Example: The Climate Research Unit Climategate Code
These are two example videos in which different arguments are made about the same source - one argues that the leaked source code is a “smoking gun” that reveals a climate change hoax, while the other argues that it does not. The arguments on both sides are made based on a huge mix of rhetorical appeals.
Video 1: CRU Source Code Explained (a Climategate exposé)
Michael Suede performs a selection of readings from source code that was part of the information exposed by the 2009 Climate Research Unit hacking incident. The presentation includes reading aloud from code comments, displaying code and comment screenshots, and discussing the snippets in the context of relevant algorithms and practices.
I discuss the actual source code that was released in the recent hack of the CRU. The source code confirms the manipulation of climate data by climate scientists…
Suede states that this reading is part of a larger project to challenge climate change evidence - not just from the CRU, or papers that cited CRU, but from any other climate research source that agreed with CRU in its findings. That challenge hinges on code snippets and their comments.
Video 2: Debunking Climategate: The Source Code A
Video 2: Debunking Climategate: The Source Code B
Conversely, the second video argues for a different interpretation of the Climategate source code based on a critique of interpretive rhetoric (e.g. ad hominem interpretation), an appeal to understanding of the culture of personality among software engineers, and the contextually specific meaning of the word “integrity” and what it signifies in the context of “data integrity” about the software and data.
One of the bigger points I hear in the arguments about Climategate is that the emails, while interesting, aren’t considered the “true smoking gun” in the scandal. Rather, the real meat is inside a package of source code and programmer’s notes that was included along with the emails.
The skeptics say that in [the code] is evidence of tampering with data and other bad behavior - and since this is source code (i.e. logic and mathematics) it is not something that can be taken out of context like a person’s words in an email can.
I feel, though, that there is a fair amount of reasonable doubt that can be thrown the source code’s way, and that a lot of the more serious claims that skeptics make about the code and what it means for Climategate, really aren’t so.
How is this code being read, by whom? How could it be read differently?
Reply by Sheldon Brown on February 8, 2010 at 5:24pm
One category of people that read from a critical insider position are collaborators. Working with others on developing large-scale software projects supposes that there are readers who will be looking at the code with intense and complicated personal interests including livelihood and professional status. Coding ethos is often directed towards these collaborations, such that the style of variable names, the size of functions or the granularity of objects are all subjects of critique and the means by which underlying thoughts are expressed - the subtext of the code. The grammar of code can be structured by external authorities - a senior project programmer - or the conventions of the company. Eccentric coding, which might provide more meaningful cultural readings, is often expunged from the code by the collaborative processes. While there is personal code, much of what is running reality is authored by a corporate body. The social schemes by which these bodies are organized around the development of the immaterial code, including the diversity of physical presence relationships between authors, would seem to be important.
Reply by Jeremy Douglass on February 8, 2010 at 6:24pm
Your distinction between eccentric “personal” code and collective / corporate “impersonal” code resonates well with the Debunking Climategate video claim that the idiosyncratic and unprofessional naming, formatting, and documentation of the code should be considered differently because it was an individual effort that was never meant to be read outside a very small group.
I like how your suggestion points us towards many other ways of talking about interpersonal code - for example, the code that results from Pair Programming methodologies, or the code culture that arises from a collective writing code that will be read or reviewed either by or in light of the views of one dominant personality - e.g. a high-ranking member of the Linux kernel team, or Steve Jobs.
Reply by Angela Ferraiolo on February 9, 2010 at 8:28am
While there is personal code, much of what is running reality is authored by a corporate body.
This is an interesting point. The corporate body is likely to have a profound effect on code style. For example: What is the effect of adopting best practices? How are those practices decided and agreed upon, by whom, and in what ways are they ‘best’? Who is privileged? Who is disadvantaged? What do nondisclosure agreements do to code styles? How do corporate cultures give rise to the private languages of proprietary code? (Actually, the rationales programmers give for resisting or accepting work in proprietary languages is sort of illuminating, isn’t it?) What can we deduce about a culture from the code it favors and the code styles it creates? For instance, what was happening in our society at the time programmers began to see object-oriented programming as desirable? What kind of a society and production environment would favor object-oriented programming over other approaches or paradigms? How are people who can’t or don’t move on to the new paradigm treated within the community?
Reply by Evan Buswell on February 9, 2010 at 9:08am
How do corporate cultures give rise to the private languages of proprietary code?
I’m not sure if this is what you meant, but actually “private language” is exactly what I’m thinking of regarding the “best practices” and other constraints that programmers have from corporate bodies. Writing within such an environment is like writing with a private language; sure, deviation would compile, but it’s still ungrammatical. Like to it your ability to parse this sentence. These traditions are usually bound to particular languages as well, e.g. you would name an object in Java as “theObject,” but in Perl it would probably be called “the_object.”
In some sense, though, coding is *always* the creation of private languages, insofar as the majority of function calls, variables, etc. in a large program are going to be things you’ve named yourself. I think that’s a big reason for open source; a programmer spends all this time making a language and then they want to talk with other people using that language. They want to build a community that can read and write in their language.
Also, regarding object-oriented programming, I know that the questions you’re asking have fairly well-documented answers insofar as the designers of these languages had certain goals in mind, and they wrote extensively about the social ills that would be cured by OOP. I don’t know too much about it, but my limited understanding is that the creation of object-oriented languages was a response to the professionalization of programming. Suddenly, there were really bad programmers working alongside really good ones, and modularity and encapsulation were needed so that the lead programmers could tell the poorly-trained programmers: “You go work on this, and I’m not going to think about how badly coded it is. I know you can’t mess with my code.” Of course, the genealogy and the present rationale are two different things.
Reply by Jeremy Douglass on February 9, 2010 at 9:47am
On the topic of the difference between the code being legible, idiomatic, or in the house style vs. the code that compiles and functions but is unconventional or almost illegible - obfuscated programming contests such as Obfuscated C are one extreme example of this difference. Another example is the output of decompilers. If you have used a good decompiler, you know that what you get back is usually functionally similar or identical to the source code that produced the program. Yet much of the higher level order, structure, and of course the logical connections and emphasis connoted by naming are stripped away and replaced with a kind of foo bar baz gumbo. Really good decompilers use a variety of techniques to try to add context and meaning back in, but without properly named parts and a narrative of functionality, decompiled code often looks like the machine’s own private language - or just a bag of full of gears.
Reply by David Shepard on February 10, 2010 at 6:00pm
To add to your point, Evan, I think that the audience of code changes because what we think of as the “progressive” path of programming paradigm production (that alliteration was intentional) isn’t as linear as we think. What I think of as the major programming paradigms, structured programming and object-oriented programming, were technologically feasible long before they were widely adopted. For example, we attribute the invention of structured programming to Edsger Dijkstra in the mid-1960s, but the language constructs that enable it (like defining functions with specific input and one exit point, and only access to local variables) were available in the second draft of the FORTRAN language specification from the mid-1950s, which apparently Dijkstra had nothing to do with. Object-oriented programming was invented by Alan Kay in the mid-1960s (or so the story goes), but was not widely adopted until the 1990s, and even the first version of the MOSAIC web browser was written in non-OOP C. It seems to me that OOP as a house style didn’t really become that until Java.
The reasons I’ve heard proposed for the rise of OOP is that businesses adopted it to manage workflow (and thus smooth out the idiosyncrasies of managing large teams of programmers); it was a tool of management against labor. This is a thesis I’ve partially synthesized from Maurice J. Black’s Art of Code and Ziv Neeman’s Building Profit-Power into this Electronic Brain, and Linux devotees who praise structured programming over OOP. One example the devotees’ point to is that the UNIX/Linux X windows windowing system wasn’t originally object-oriented. Oddly, though, the Windows 95 API was not object-oriented, nor were later versions until at least 2002. For example, to create a new window, the programmer calls the CreateWindow() function rather than, say, instantiating a new WinAPIWindow object. The programmer also must define WinMain() and WindowProcedure functions in the global namespace, rather than, say, extending a hypothetical WinApplication class and extending the member WinMain and WindowProcedure methods (I’m getting this from the following tutorial: http://www.relisoft.com/win32/winnie.html). So suggesting that it’s a matter of trying to isolate coders from sensitive system functions doesn’t seem like the real purpose when the company largely blamed for enforcing this separation seems not to have been particularly keen to enforce the OOP paradigm on application developers.
The technological problem OOP seems to have been most successful in solving is abstraction from hardware, which is a corporate problem of market reach - that is, having to develop software for multiple platforms costs more than developing a single version. OOP seems to have reached its apex with Java, in which programs themselves are classes instantiated by the JVM when it loads. Java itself was created to free the programmer from having to negotiate the differences between Windows and Macs, or Sony and RCA DVD players. Microsoft .NET is designed to do the same, and in .NET, Windows applications do use an OOP API.
But, just because we think of OOP as the dominant programming paradigm now, the creation of a dominant paradigm generally seems to lead to the rebirth of simpler programming paradigms. Structured programming was adopted on the System 360 project in the 1960s and 1970s, but most early PCs came with a BASIC interpreter on a chip, which on IBM clones was later folded into the software level in MS-DOS. These versions of BASIC, as anyone with affectionate memories of programming Apple II computers will remember, did not allow structured programming. Structured BASIC really didn’t become popular until QBasic and Visual Basic, which later came with DOS. PC applications were written mostly in C, BASIC, or Assembler.
Additionally, Java was supposed to be the major web language, but has lost ground to PHP. PHP’s innovation (some would say its greatest annoyance) is its ease of use and its reversion to relatively unstructured programming, which seems technologically regressive. Writing a Java web app requires extending a base HTTPServlet class at the minimum and enforces strict separation of code, content, and data, while PHP allows web app development to be done with function calls inlined in HTML. Up until PHP 5, PHP’s OOP had been fairly weak, and it continues to be much less developed than Java’s. PHP has become probably the dominant web language because of its simplicity, and because the alternatives (Java, .NET, Python, and PERL) generally require significantly more work for even simple apps. Thus, Wordpress, Joomla, Moodle, and most web software (maybe even Ning?) use PHP. So we have a programming language that is technologically regressive (a vague concept perhaps, but one that seems useful against the many “evolutionary” accounts of technology) that wins out because of its simplicity. While OOP is the dominant paradigm on desktop applications and in some web applications, a language intended to free the programmer from having to think in those paradigms became popular.
I’m beginning to theorize that programmers seem to envy unstructured programming and therefore create tools that allow them to write less structured code, like PHP or LINQ. Languages that simplify a common task by integrating previously-separated concerns (as PHP simplifies web programming by mixing presentation, logic, and data access) inevitably adopt more complex features because their simplicity makes more complex tasks possible. Programming language development seems like an ouroboros: adding more features to manage more complexity eventually creates a language so unmanageable that an additional layer of abstraction is added which allows this complexity to be managed more easily.
Reply by Jeremy Douglass on February 11, 2010 at 2:20pm
David,
Thanks for these observations on object-oriented programming. From what little I know about how various partisans narrate the history of programming languages differently (including contested origin dates, different generational schemes and family trees, etc.) I’m a bit nervous about broad claims on programming evolution, for the same reason I’m initially nervous about broad explanations of, for example, German vs. French aesthetics. I’m not saying such things can never be useful, I just feel more comfortable when they proceed carefully, driven by specifics.
But to be more specific to your thoughts on OOP: if evolution is a biological metaphor about fitness, it isn’t clear to me how a web scripting language like PHP could be said to exhibit evolutionary regression unless it lost OOP features that it once had. Whose regression is also important. If we are talking about a few internal developers and the languages they had used in their lives, we might get one story, but if we are talking about public release to a development community, another. For example, Sun Java was publicly released in May 1995, PHP was released in June 1995, and many developers in their initial surges were coming to them from all over the map, including cutting their teeth on programming / scripting for the very first time with them.
A more general idea I take from your points is that we should look to historians of computer languages to see what useful economic, cultural, political and ethnographic work they have done (or haven’t done) that connects to the language itself, and how it might be used from or inform a CCS perspective.
Reply by Max Feinstein on February 11, 2010 at 12:29pm
We have a programming language [PHP] that is technologically regressive (a vague concept perhaps, but one that seems useful against the many ‘evolutionary’ accounts of technology) that wins out because of its simplicity.
Perhaps the prevalence of PHP re-writes the definition of technological progress, so the term not only considers how powerful a language may be (e.g., the presence or absence of comprehensive OOP support) but also measures its accessibility and easy of use. Instead of using functionality as the primary gauge for a language’s technological power, we might equally consider the benefits ushered in by a language’s ability to mix previously independent entities, as you’ve shown that PHP does with presentation, logic, and data access. Framing languages in this light could add yet another dimension to CCS by providing new ways to think about programs, or in this case, programming languages, and how they evolve over time according to the needs and desires of those who work with code. You’ve already alluded to this idea with the suggestive term “evolutionary accounts,” so maybe we can expand on it by enumerating the accounts other than technological progress. Such an exercise might be beneficial for the CCSWG, especially in the context of code critiques.
I’d also like to shed some more light on the distinction between personal and corporate code. Sheldon brought up this topic when he said “eccentric coding, which might provide more meaningful cultural readings, is often expunged from the code by the collaborative processes. While there is personal code, much of what is running reality is authored by a corporate body.” I suggest that the distinction between eccentric and corporate is less clear than what has been noted already. For example, in my list of candidates for code critiques, I’ve included a portion of the Windows NT source code, which was leaked from Microsoft in 2004. The leak gained notoriety not only because of the proprietary nature of Microsoft code (and most other corporate code), but also because of the eccentric commentary woven throughout the entire piece of software. Take a peak at this kuro5hin article that critically reads segments of the leaked code. It’d be great to get our hands on more corporate code, but that seems to be a practically unattainable ideal.
Reply by Andrew Davis on February 23, 2010 at 3:17pm
It is rarely true that a corporate dialect is somehow a community wisdom or summation of best practices within a corporation. Dialects rarely evolve within a corporation in my experience. The ever-present risk factor for a change of dialect inserting bugs or the additional work for already late software developers just doesn’t let large dialect changes make it over the code critic hill.
In a meager sampling of 6 corporations, all corporate dialects were the work of one or two members of the first team of engineers in the first month of a corporation or major new project. I was ‘that guy’ at 3 of those 6 corporations. I write down a list of best practices, garnered from the previous N-1 corporations and that becomes the corporate standard. Sure, if it had been garbage, the engineering code critics would have done their job and buried the initiative. But the critics rarely added content to the dialect themselves.
Although this fiat style might be assumed, it rarely works out as the reason code in a corporation looks homogeneous. Very few engineers look at a coding guide, style guide, or dialect direction at any point in their first 6 months of a new job. Generally code is stolen, borrowed, referenced, lib-ified, etc. So, the coding style of the most prolific programmer quickly becomes the de facto standard. So, the first set of engineers on a project ‘win’ and get to lay down fresh tracks of code in once empty files as well as setting the standard for a corporate dialect.
Reply by Mark Marino on February 12, 2010 at 11:44am
David,
Have you read Wolfgang Hagen’s “The Style of Sources,” from Wendy Chun and Thomas Keenan’s edited volume, old media, new media? It seems like a text that would provide some fodder for this line of argument. Hagen (as translated by Peter Krapp) sums up his thesis as:
for decades, the arche-structure of the von Neumann machine did not reveal that this machine would be more than a new calculator, more than a mighty tool for mental labor, namely a new communications medium [which I believe Lev picks up in his new manuscript]. The development of FORTRAN demonstrates all too clearly how the communication-imperative was called on the machine from all sides. The imperative call obviously could not be detected in the arche-structure of the machine itself. It grew out of the Cold War, out of the economy, out of the organization of labor, perhaps out of the primitive numeric seduction the machines exerted, out of the numbers game, out of a game with digits, placeholders, fort/da mechanisms, and the whole quasi-linguistic quid pro quo of the interior surface of all these source. (173)
Reply by Julie Meloni on February 14, 2010 at 10:44am
Framing languages in this light could add yet another dimension to CCS by providing new ways to think about programs, or in this case, programming languages, and how they evolve over time according to the needs and desires of those who work with code.
I like this possible dimension of study, and to support that I offer some information about the development climate specific to PHP and its use in industry from its early years. Bear in mind that these are generalizations based on a) my involvement (mostly as a lurker) on the PHP-related mailing lists from 1999 until about 2003, and then b) my experiences as a consultant in enterprise product development from 2002 through the present.
As Jeremy notes below, Java was released in 1995 and PHP also in 1995. But it would be a good few years before PHP really gained any traction - 1998 or so. Classic ASP was released in 1996, had a revision in 1997, and settled/stagnated in 2000. JSP popped on the scene in 1999, specifically as an answer to PHP and ASP, which even in their nascent stages were seen as game-changers.
But what was the question? The question, I believe, was how best to leverage people who were “coming to them from all over the map, including cutting their teeth on programming / scripting for the very first time with them” - as Jeremy noted below. I completely agree with this statement. The cultural context for the development of these programming languages - or, more specifically, the acceptance of “technologically regressive” languages (as one could easily argue PHP, ASP, and JSP were, to varying degrees and for different reasons) - had everything to do with the rush to put in place anything vaguely resembling a dynamic interface through which users could do…something…(generate content, etc) and the corporation behind the interface could collect…something (data, data, and more data).
For example, when responding to a RFP, my company would often produce two: the way we would create a product in a perfect world (full of OO goodness) and the way we would create the product in fairly procedural, loose, easily remixed code - not buggy, and certainly fast & secure, but not “the best” textbook way to produce software. It was rare indeed that the former won out over the latter.
That is not to say that you can’t create a lovely, flexible, OO application quickly. Of course you can, with the right resources. But a lot of the available resources (e.g. new hires filling the ranks) were just cutting teeth on any sort of programming, and the natural move was to procedural programming and scaffolding knowledge before being able to conceptualize and produce OO code. But, then, many corporate cultures allowed them to stay in the procedural/loose comfort zone, and so this type of application development was perpetuated.
Reply by Andrew Davis on February 23, 2010 at 3:53pm
http://www.joelonsoftware.com/articles/LeakyAbstractions.html
What if language lifetime were about the leaks in the abstraction a language creates? How many leaks and how to learn them, code around them, or code through them?
For instance, Java has JNI as a kind of a “oops we forgot about that” way of dropping the developer out of OO mode into a raw, underbelly of Java way of adding functionality when the Java OO abstraction leaks. Now, the problem with JNI is that it isn’t write-once-run-anywhere; it isn’t cross JVM compatible, etc. So it so totally breaks your Java app that you have to give up the very things you picked the language for in the first place!
Now, PHP…can you use it like OO, yeah. Can you get at the underbelly and code around it if the abstraction fails, definitely.
So if language acquisition is viewed as the sum of the language and the abstraction failures, perhaps Java is actually significantly more complex than PHP to acquire and thus the long term trend toward PHP?
Nothing more than economic opportunity cost. At first glance.
Reply by Gregory Bringman on February 8, 2010 at 7:04pm
In regard to the need to move beyond “The Two Cultures” with the examples you give of code reading in everyday life, if I remember C.P. Snow correctly, it seems he calls (in The Two Cultures) for literary artists and scientists to unite to solve common problems of the industrial revolution, what some now consider as the information “revolution”. So in the inaugural moment of his Rede lecture and of the so-called “Third Culture” (if we link directly back to Snow), technology is the site for this problem solving/collaboration. So I wonder then, from Snow, if working with artifacts of code or solving any technical problem does not obligate us to reach a level of “third culture” interdisciplinarity in which we indeed move beyond “The Two Cultures”. That is, contemporary technological conditions strictly imply this discursive position (as your examples attest…)
Reply by Jeremy Douglass on February 9, 2010 at 8:46am
I believe (but haven’t yet checked) that Snow introduced the Third Culture concept after his 1959 lecture - in the 1964 second edition of his book, The Two Cultures and a Second Look. There is a variety of Third Culture literature out there that might be relevant to that, as well as some two-culture-reconciliation literature, like Gould’s The Hedgehog, The Fox, and the Magister’s Pox. Various parties weighing in on the debate have either claimed the two-culture distinction was a) fundamental, b) overblown, or c) fundamental and overblown.
I very much like your point that we are both part of and beyond this conversation by necessity, due to the way we are technically and historically situated. My own hope in mentioning “two cultures” at all was not to start a pitched battle, but to signal the way we could be mindful of past Us vs. Them narratives and so move beyond them. Personally, I’d rather not call it a Third Culture - I’m more of the mindset that there are a multitude of cultures at the outset.
One final point I should make regarding Snow is that I tried to sneak it in without really taking the time to talk about the way that the ideal programmer and ideal cultural critic that I see as CCS straw men both do and don’t map against the ideal scientist and ideal humanist that Snow and others have discussed. To my mind, some of this has to do with the difference between science culture, (software) engineering culture, and craft culture. Other differences relate to the huge changes in the methods of criticism from the 1930s stereotype of high criticism that Snow sees as the dominant paradigm in the late 1950s - looking at the recent emergence (for example) of Media Specific Analysis and then Digital Forensics, it isn’t clear to me that a distinction between hermeneutics and the scientific method is actually a useful way of describing what people are doing.
Reply by Mark Marino on February 8, 2010 at 11:38pm
Jeremy,
What a wonderful piece to bridge the gaps that I opened, unintentionally, in Week 1. Certainly a provocative and prodigious post, as only you can generate.
Well, let me dive right in. I love this idea of code reading “in the wild.” While folks dig through their bookmarks for examples…
Following your lead with Climate Gate and thinking of related -gates, let me offer this little flashback to #amazonfail. This was the moment when GLBT books seemed to be mysteriously slipping in their sales rank on the online booksales giant, where “location, location, location” is everything. In this post from Avi Rappoport, “Amazonfail: How Metadata and Sex Broke the Amazon Book Search,” he tries to reconstruct the organization of the database. In one passage, he offers,
From this and other evidence, I believe there is a flag on each category, defining whether it is adult or nonadult. When a category is flagged adult, the system automatically suppresses the sales rank and the main search results for all items in that category. This is supported by the observation that many Kindle editions have a separate listing (under the Kindle category) and so some books delisted in book format were still available in Kindle format, and vice versa.
Later he writes:
“In this day and age of Cloud Computing, SaaS, and web applications, data is becoming increasingly just as critical as code.”
This is a valuable example of someone trying to discern the operations of the code upon its data, or rather how that data is organized. (I don’t think we need to develop critical database studies to include such reflections.)
More importantly, I think this question speaks to one concern brought up in the CCSWG “code critiques” forum by Aymeric Mansoux Title: Critical Black Box Code Study****Posted by Aymeric Mansoux on February 5, 2010 at 3:18pm in Code Critiques
Source: Ning, Inc - Marc Andreessen, Gina Bianchini
Relevant Dates:
Language/s: PHP, Java
Code: The code is proprietary and cannot be accessed.
**Summary of code’s function:**The code powers the Ning platform that we are currently using for this working group. The code belongs to the category of so-called “social software.” As such it provides software metaphors for social links, groups and communities. These metaphors can be experienced via a web application that can be accessed from a web browser, while all the data remains held by a centralized server, or server farm, or cloud owned, or rented by Ning, Inc. This summary is an easy guess from a user perspective, the rest of the code functionality is unknown.
Your Critique: At risk of saying the obvious it is increasingly difficult to avoid using social software, yet these programs are, from an algorithmic perspective, defining new control structures that have an impact on our online behavior, our consumer habits, our work, our privacy etc. These new forms of social control are expressed as code written by private groups and driven exclusively for commercial purposes, outside of any possible regulation.
Questions for the Working Group? Should critical code study limits itself to FLOSS, one-liners, abandoned material, public domain or fair-use resources? What kind of strategies can we come up with to provide a critical code study … without any code?asking,
* Should critical code study limits itself to FLOSS, one-liners, abandoned material, public domain or fair-use resources?
* What kind of strategies can we come up with to provide a critical code study … without any code?
Sometimes, when we don’t have the smoking or abstaining-from-smoking gun, we spend our time trying to derive the operation of the code, reading it from its effects. I believe you yourself have somewhere referred to this as the “implied code.” In any event, #amazonfail represents a moment when the twitterati and blogging circles began to spiral around questions about how information was being processed by a particular piece of softwhere, speculating critically on how it might be negatively impacting real-world conditions.
Again, no real code here, but does this relate to what you are describing?
Reply by Jeremy Douglass on February 9, 2010 at 10:43am
Mark,
I certainly find the “#amazonfail” incident to be relevant as an example of public collective interpretation, and I find it relevant not least because I have very little invested in policing the border between Software Studies and Code Studies.
Thanks for pointing out Aymeric Mansoux’s “Critical Black Box Code Study” provocation, and for making the connection to the concept of “implied code,” which I originally defined as “an interactor’s mental model of the operational logic of the interactive work.”
The emergent understanding of any “black box” software process is about constructing and then critiquing a hypothetical or implied code, rather than dealing with the code itself. In the case of #amazonfail, constructing an implied code (along with implied programmers and management) is certainly what people did. Importantly, they did this in a variety of ways: through attempts at applying the scientific method, contextual inference, and wild speculation.
Of course, this performance of public software studies in #amazonfail was different from the CRU Climategate debate of public code studies precisely because there was no code. Database architecture is code, as are views and server side scripts. If we had a snapshot of these things, the data, and the internal editorial culture, we could really do code studies.
It is my belief that authors on blacklisted gender and sexuality topics were correct to react with #bugmyass and with more general paranoia. Without knowing how they were marked by the system before, or how that has changed, there was no concrete vocabulary to engage Amazon on reform. At the same time, I think people pointing to “there is no perfect cataloging” or “corporations are cussed about PR” misunderstand that there was probably also a fundamental technosocial conflict here. I’d venture that, as with Google’s PageRank, Amazon’s Sales Rank developers are working partly in an antagonistic relationship with the many cultural constituents who seek to exploit and manipulate the algorithm for their own benefit. If that is the case, our preferred stance for Amazon (perfect transparency) isn’t possible - or at least they believe it isn’t possible, and there are complex internal and external reasons for that belief that could be the subject of another critique in relationship to the Sales Rank algorithm itself.
So, to sum up:
-
Yes, I find #amazonfail an extremely relevant example of feral software studies.
-
No, I don’t think it is code studies.
-
But, I hope it becomes code studies someday - if anyone can ever get access, that would be a great article.
Reply by Max Feinstein on February 12, 2010 at 1:28pm
I’ve been searching for computer science publications that are concerned with the philosophical aspects of programming. I found a number of interesting topics, and while they might not be good candidates for bibliographic entries, I think they’re good leads and could help us find CCS-appropriate texts for analysis:
The introduction offers a brief overview of Unix philosophy:
The Unix philosophy (like successful folk traditions in other engineering disciplines) is bottom-up, not top-down. It is pragmatic and grounded in experience. It is not to be found in official methods and standards, but rather in the implicit half-reflexive knowledge, the expertise that the Unix culture transmits. It encourages a sense of proportion and skepticism - and shows both by having a sense of (often subversive) humor.
Such topics as these are covered in the article:
Rule of Clarity: Clarity is better than cleverness.
Rule of Simplicity: Design for simplicity; add complexity only where you must.
Rule of Transparency: Design for visibility to make inspection and debugging easier.
Rule of Least Surprise: In interface design, always do the least surprising thing.
This article links to an extensive collection of lessons on Unix philosophy. In that collection is a page on the history of Unix + OOP, which has particular relevance to this discussion in the Week 2 thread.
Another notable page from the lessons on philosophy is The Importance of Being Textual, which contains language reminiscent of some discussions on the CCSWG:
Pipes and sockets will pass binary data as well as text. But there are good reasons the examples we’ll see in Chapter 7 are textual: reasons that hark back to Doug McIlroy’s advice quoted in Chapter 1. Text streams are a valuable universal format because they’re easy for human beings to read, write, and edit without specialized tools. These formats are (or can be designed to be) transparent. (Emphasis mine)
Another search I’ve been trying is “computer code” in various news archives. I didn’t have much luck in historical databases on Proquest or JSTOR, but Google’s news archive has yielded some promising results. The search term I started with is “computer code.” The search even provides a graphical analysis of the distribution of articles over time:
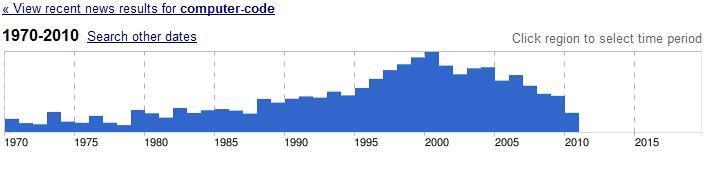
(This graph represents nearly 14,000 news articles.)
A 1991 New York Magazine article about “the many tongues of computer code” reminds me of the discussion on a random maze program that’s currently taking place in code critiques.
A 2004 Herald Tribune article reports on how computer code led authorities to a suspect in a murder case in Kansas City.
Has any1 considered the possibility of looking @ shorthand txt as computer code? This 1999 Chicago Sun-Times article describes shorthand as a language developed by kids using instant messenger programs, email, and cell phones. I’m not sure if this is an appropriate route for CCS, but there’s some good discussion about language and computers.
I think these news reports provide a number of avenues for our studies, but the real challenge will be to find code contained within them.
Reply by Mark Marino on February 10, 2010 at 11:06am
In answer to your original call for code in the wild, I was searching through some legal rulings and I came across the case of Snuffle, in Bernstein vs. United States Dept. of State.
Now in this ruling, as taken from another source:
The court began by stating what its view of source code is; namely, that source code is the text of a program written in a “high-level” programming language, such as “PASCAL” or “C.” n216 A critical factual determination by the panel decision included that a distinguishing feature of source code is that it is “meant to be read and understood by humans and that it can be used to express an idea or a method.”
The court recognized that since source code is destined for the “maw of an automated, ruthlessly literal translator”-the compiler-a programmer must follow stringent grammatical, syntactical, formatting, and punctuation conventions. As a result, only those trained in programming can easily understand source code. n218
For example, the following is an excerpt from Bernstein’s Snuffle source code written in the programming language C: n219
for (; ;) ( uch = gtchr(); if (!(n & 31)) ( for (i = 0; i64; i++) 1 [ctr[i] = k[i] + h[n - 64 + i] Hash512 (wm, wl, level, 8); )
I found this section quoted in this article: “When Efforts To Conceal May Actually Reveal: Whether First Amendment Protection Of Encryption Source Code and the Open Source Movement Support Re-Drawing The Constitutional Line Between the First Amendment and Copyright ” by Rod Dixon in the Columbia Science and Technology Law Review.
The article begins, provocatively enough:
Computer source code is speech-that is the argument advanced by privacy advocates and cryptographers, who recently obtained the support of the Ninth Circuit in Bernstein vs. United States.
No doubt, such a claim raises the ears of critics in the room, and this article and this case fall squarely in the domain of the copyleft debate, though I believe they are instructional here as well.
Obviously, arguments about the nature of code go far beyond the academy, yet what has been happening in the courts seems to call for the analytic tools we are developing.
The Snuffle case is one we should discuss further, perhaps in code critiques.
Now, originally I planned to call this code in the wild, but it’s not any more. Among the articles written about this case include one by CCSWG Member: Gabriella Coleman. Her article “Code is Speech” should definitely be added to our reading list.
Gabriella, do you want to comment a bit about this “code in the wild”?
Are there others who look at legal rulings on code? Do you find much code in it? Recently, an attorney friend of mine, Sal Kaihani, explained to me that courts like to describe code rather than read it.
What other examples of code in the wild turn up in legal rulings?
Reply by Gabriella “Biella” Coleman on February 11, 2010 at 7:59pm
The code referred to above may no longer be “in the wild” and we might even say that in some cases and circumstances code has “gone wild,” exploding beyond its initial public into other domains, even traveling via the bodies of programmers on their shirts as was the case with DeCSS and previously chunks of the PGP code.
In terms of other legal arenas where code might appear, something that comes to mind is patent dispute cases where some company (who is accused of infringing the patent) is ordered to pony up some code (the software patent, however has no source code, just a general description of process). I have not followed any of these cases but there must be a number of them. How and in what capacity do the courts read vs. describe the code to determine infringement would be interesting to further explore and compare to copyright/free speech cases that deal with code.
Reply by Jeremy Douglass on February 12, 2010 at 11:06am
Gabriella,
For some reason I’m reminded of Jill Walker’s “Feral hypertext: when hypertext literature escapes control”.
This paper presents a historical view of hypertext looking at pre-web hypertext as a domesticated species bred in captivity, and arguing that on the web, some breeds of hypertext have gone feral. Feral hypertext is no longer tame and domesticated, but is fundamentally out of our control.
Without going too far down the rabbit-hole of naturalism and evolutionary metaphors, I wonder if it is useful for us to think about feral computer languages, code bases, and discourses about code - often bred in captivity, but now out of control.
Perhaps in that light, aspects of CCS itself are a species of feral computer science? Although according to whose nature, whose control?
As to court documents. One of the amazing things about court documents is that many of them contain statements from judges in which they define a) what software is and b) what code is for the purposes of the trail. These are often articulate, reasoned philosophical stances, and quite interesting. Another thing to collect for the bibliography…
Reply by Gabriella “Biella” Coleman on February 14, 2010 at 12:13pm
Another important program/code that circulated pretty globally (and in tension with its legal status) was the Unix source code, and in specific Lion’s Commentary on Unix, a textbook that helped to secure UNIX as a beloved OS among many technologists. I love the cover of the book as it refers back to its history of circulating photocopies:
http://ecx.images-amazon.com/images/I/51ESMPKM6ML.jpg
The story of UNIX’s promiscuous circulation and its importance for Free Software is told in Chris Kelty’s Two Bits in chapter 5: http://twobits.net/
There is another chapter (6) where Kelty looks at how a controversy over a small bit of code led RMS to establish the GNU General Public License. I will add these to our bibliography as well.
Reply by Jessica Pressman on February 11, 2010 at 8:56am
I am finding myself drawn to the performative aspect of CSS as it emerges in both Jeremy and Mark’s presentations. As I only just recently posted to Mark’s presentation from last week, I was struck by his oral reading of code and his provocative call for the value of this practice. In Jeremy’s presentation, I am again interested in the different ways in which code is represented - visually, aurally, and in embodied performances. Contained within Jeremy’s post are video clips that contain code displayed on computer screens as well people describing code across various affective registers. I am curious to see how this CSS discussion group proceeds to present code and also pays attention to the representation of code as a practice that itself can take on aesthetic, political, and critical valences.
Reply by Mark Sample on February 11, 2010 at 9:00pm
Your highlighting of the performative aspects of reading code reminded me of this TED talk by Rives, in which he tells a story about a string of emoticons (which surely counts as code): http://www.ted.com/talks/view/id/383.
Reply by Jeremy Douglass on February 12, 2010 at 12:01pm
Mark,
In addition to examples like the Rives talk, I’d suggest another approach to the question of visual interpretation.
are all utilitarian visual rhetorics of code. Of course, the same code can be tinged with an ancient or contemporary, corporate or amateur air just by styling it with different colors - just as some code can appear slightly messy or rigidly organized if presented using fixed or dynamic-width fonts. This extends to code vocabulary and style for languages, libraries, and APIs. The same number of lines and keywords in Cocoa can look and feel extremely verbose (in both a good and bad way), because it uses names like )
Reply by Jeremy Douglass on February 12, 2010 at 11:37am
Jessica,
Yes - how does code get presented and performed, audibly-or visually for that matter? These Youtube-readings and showings (for example, the one with code set to a sound track with lyrics) very much connect back to Mark’s performance last week and how you are discussing it there.
To me, the idea of reading code with aesthetic emphasis, paraphrase and quotation, etc., is not just an issue of speculative aesthetics. For example, auditory interfaces for blind programmers are a real software engineering problem. Code-out-loud isn’t just the domain of poets and interloping humanists. But the second you imagine or recognize any utilitarian context for code-out-loud, you realize there is also a significant aesthetic dimension to the voice even if you try to treat it strictly as a utilitarian user interface problem - whose voice? What are the speech conventions that make the practice concise and fluid - surely not just reading one character at a time? Does tone separate data from process? Are code comments whispered or shouted? And if this is done through speech synthesis, what is it synthetically referring to? How in practice do we map functionality viscerally against what Pinsky terms the medium of the human body, “the column of air inside the chest”?
Reply by Hugh Cayless on February 11, 2010 at 10:31am
Hi Jeremy,
You asked me what my take on the CRU code (and your approach to it) was, given my critical evaluation of the annakournikova code Mark posted as “inept” and my conclusion that the most interesting thing about it was the social context. I’m not prepared to say that the CRU code is inept (not having spent much time reviewing it). It certainly isn’t at the same level of incompetence.
I think code almost has to be read in context. It is very hard to properly appreciate code without an understanding of what it is trying to accomplish, for example, so the motivation(s) of the programmer(s) are often important. In my coding experience, a lot of time ends up being spent on trying to figure out the goals of the creators of legacy code. Sometimes these are made clear in the comments, but more often not.
But there are many contexts here. I see the programmer, in a secure enough space that he/she (do we know the programmer’s gender? Would it matter?) felt comfortable expressing dismay at the complexities of the data and his/her ability to handle them. Then we have the political context in which the scientists knew they were operating, and which invaded the programmer’s secure space with the exposure of the files. And then there are the various analyses which Jeremy has given us: conspiracy theorist, “corporate gaze” (to borrow a nice term from Evan Buswell), and sympathetic fellow-coder.
So as with the annakournikova code, the context is very powerful, and interesting. Is it more interesting than the code? Do we risk letting the layers of context obscure our view of the code? I suspect this code is worthy of more attention than the virus was.
Reply by Jeremy Douglass on February 13, 2010 at 1:17pm
Hugh,
Very interesting point about contexts. In response to your question about the gender of the actual programmer, I’ll add some more context - although “does it matter?” is a very good follow-up question. I’m positive that it doesn’t matter to the issue of whether a particular set of functions correspond (or not) to a predictive model of current global temperature trends and their consequences. I strongly suspect however that the identity of the programmer matters in the public debate - either as an imagined construct, or as a real (although still imagined) person.
In talking about the CRU programmer, the second Debunking videos show (00:50) a cartoon of a harried male programmer as a stand-in, and I suspect that the cartoon probably corresponds to the mental image for many followers the debate.

The identity of the actual programmer(s) is simpler but muddier than in most cases, where an open source or corporate codebase may have hundreds or thousands of authors, but the changes may be checked in with an identities registered against every change. With CRU, the programmer gaining the most attention was the author of HARRY_READ_ME, who was likely Ian ‘Harry’ Harris.

Of course, Harris was “the programmer” at the time of the leak, but wasn’t in fact the author of much of the code - he was maintaining and attempting to iterate a complex, poorly documented code base that was written earlier, apparently by Tim Mitchell and/or Mark New. This leads into the some of the issues about authorship that are so interesting in code - in theory, code development as practiced in a versioning system affords the opportunity to talk about the collective production of an idea in a very concrete and fine-grained way. In practice, however, we are often left reading tea-leaves, even when in the midst of conversations that require algorithmic literacy or programmacy to navigate them.
Reply by Mark Sample on February 11, 2010 at 8:55pm
Jeremy, thanks for this enormously productive inquiry. Your list of “real code readers” was especially valuable - it’s a reminder that code (like science in general) needn’t be left to the coders (or scientists). As someone who’s only dabbled in code, tweaking some PHP here, cursing some ill-fated Inform attempts there, I can easily find myself out of my depth among the more accomplished programmers here.
One aspect of your opening lines - when you run through reference, citation, quotation, and illustration - reminded me (though there was no clear logical reason why it should have done so) of the four modes of exegesis developed informally by medieval church scholars to read the Bible: historia (a literal interpretation); allegoria (the allegorical meaning); tropologia (a moral interpretation); and anagoge (the eschatological interpretation). It’s probably the wannabe medievalist in me, but I wonder if we might borrow from this four-fold sense of exegesis as we read and teach code. I’ve always found this rubric of four senses to be quaint at best (in a Northrop Frye kind of way) and misguided and dangerous at worst. But now I’m thinking there might be something here we can salvage, even if tangentially or reactionarily.
Reply by Jeremy Douglass on February 12, 2010 at 12:31pm
Mark, I agree that typologies of exegetical modes for code would be good vocabulary to have at hand. Frye is a good reference point, in some ways, because his holistic description of “centripetal” and “centrifugal” criticism captures some of the tensions within the CCS group itself around how to read code.
I wouldn’t be surprised if narrative theory in general (and perhaps New Criticism in particular) turns out to provide a lot of useful vocabulary and rhetorical moves for thinking about code. I’m thinking about work like Cleanth Brooks in “Irony as a Principle of Structure,” and what analogous kite-tails help code fly under the fingers and the through the mind of the programmer. I’m also thinking very specifically about of Empson’s “Seven Types of Ambiguity.” The belief that code is unambiguous (to the compiler and to the programmer) seems particularly pernicious to me, and we could use a good authoritative exploration of code ambiguity as one foundation stone for larger projects.
Reply by John Bell on February 12, 2010 at 4:07pm
Code has many real and ideal readers, with many goals. One of these (and an important one) is the ideal programmer. Another is the ideal machine - a compile, VM, or scripting engine. In one particular story about these ideal readers, the ideal programmer is purely motivated by functionalism, while the ideal compiler engages in an interpretive procedure untroubled by ambiguity. Rather than detail this ideal, I propose a dose of the real.
I’d actually like to pursue that ideal for a moment, just because I think the pursuit-if not the actual definition-might lead me back around to looking at the real in a slightly different way.
While I know you were trying not to go into detail, I think there is a very significant piece of the story that needs to be included: how, in the frame of ideal programmers or machines reading code, would we define the ideal user? Easy jokes aside, it seems like the ideal user has a wider range of possible traits than the programmer or compiler. For one thing, they don’t even read code per se. Their role in the system could be to define or evaluate the functionality that the programmer implements, or to execute the program the compiler generates, or even just to call up the help desk to let the programmer know that their code isn’t ideal.
I think that including that first role, where the user-specifically, the user’s needs-helps to define the functionality of the code, changes the narrative of this story of ideals significantly. The ideal programmer is not usually creating a program ex nihilo (well, unless they are), they are finding the ideal path to implement functionality that is defined outside of the context of writing code altogether. Even after the code is written, the user is constantly redefining the functionality of code by applying it in ways that the programmer may not have expected/intended (Twitter is a great example). Separating these two roles changes how code should be read.
In the case of the climate change videos, the point of vulnerability that is being used to attack the code is that the user role and the programmer role are filled by the same people. All of the questions about code formatting and professional presentation are at best secondary concerns, and at worst straw men. The base claim that’s being made is that the user influenced the programmer to produce a piece of code that functions in one way while stating that it functions in a different way. If the user and programmer had been different people or organizations then it would be easier to interrogate that claim, but here (and in many cases) they aren’t and so opposing sides are left to extrapolate intention from function.
To bring this back around to the discussion about corporate code vs. personal code, I might suggest that one of the fundamental lines between the two is that corporate code does separate the user and programmer roles while personal code does not. This is one of the stumbling blocks that open source has been trying to get beyond for years: how should we resolve the difference between “scratching a developer’s personal itch” (TM ESR) and writing software that is relevant and useful for the non-developer? One requires a user/programmer while the other requires the perspective of separation; it seems that only the most talented programmers are really good at being both at once (ideal programmer++?).
So what happens if we treat all the real code readers on your list as users, only without the extra abstraction level of actually executing the code? All of the [$user_class] reading for [$goal] readers are really attempting to define the functionality of the code they’re reading by inflecting it with [$goal]. That might be a bit of an obvious statement, but the problem is when a reader then attributes the influence of a previous user to the programmer.
I certainly don’t mean this to imply that code should only be read reductively. I mostly mean to say that there is a line between a critical reading of programmer-implementation-functionality and a critical reading of user-program-functionality that should be acknowledged, even when the programmer and user are the same person. There is still a vast amount of room for play, creativity, and genius (or not) within both of those spaces, and readings of the code should recognize that. However, there is a danger-particularly in corporate code-of mixing the two during interpretation when the reality is that they are two separate things, and the first CRU video seems to demonstrate that conflating them can lead to bad results.
Reply by Jeremy Douglass on February 13, 2010 at 8:00pm
John, I’m still thinking through your proposed “ideal user” (of the software) and trying to come to grips with how and to what extent it connects with my list of various reading roles for code. Looking at my own use of “ideal programmer / compiler” I’m also thinking about the parallels with the “implied reader / author” from literary theory. Perhaps the use of the “implied” (an imagined role that is actively constructed while reading the code) is helpful for what you are talking about here.
While reading the CRU code, we construct an implied programmer (or more than one) from what we read, and this programmer (but ideal, but probably no) may or may not have any relationship to the real programmer(s). Some readers construct an implied CRU programmer who is deceitful but incompetent, while others construct one who is earnest but beleaguered. Readers of just the logs or comments will construct this person differently from readers with procedural literacy.
Now, the code itself implies these things to a reader - we might learn in the news for example that Harris was hampered in his duties due to drug addiction (he wasn’t), but this new view on Harris isn’t reflected in the Harry that the code itself implies. Code may likewise indicate or just imply a compiler, software environment, expected data, and set of use cases to varying degrees of specificity (or not at all). So, it is a very interesting observation that code has an ideal user that is a part of the ethos of the code. Is this a user function, in the sense of an author function? A user story in the mind of the programmer, perhaps one commissioned and then passed down from management?
In the case of the CRU, the users are not entirely the programmer, although the programmer is certainly one of the users (but isn’t the programmer almost always one of the users?). Instead, the CRU users may have been working in offices 10 feet away from the programmer, and were not abstract at all. They were real scientists in all their messiness and imperfections, and the program was haltingly revised for them in reaction to their crises and shifting daily concerns, when perhaps it should have been written for the ideal user, which (we might claim) should have been Science.
At least, that is what I read in the code. But then, what I’m doing is constructing the programmer’s implied user from the code and context.
Finally, to connect this back to my list of Who Reads Code:
I’m not sure that all of my examples connect directly to use - for example, the lawyer reading breathalyzer code may not be planning to use a breathalyzer, but is intensely interested in how its functions interacted with his DUI defense case clients. Similarly, most of my Easter-egg hunters by definition are uninterested in the functionality of the code, and instead simply want to suck the marrow from it.
Still, in many examples this user idea makes sense to me. One of the items I listed was “hackers reading for exploits” - an interesting case of a code reader, as the hacker is also often a user of the code/software as well. Now, I think you could argue that this hacker is almost never the ideal user for whom a web application programmer develops her pages. In very few cases will programmers actually focus on this hacker as their development user story - especially in the specific case of the code the hacker happens to be reading. And yet, while this hacker is almost never an ideal user, you might easily say that they are often an implied user. Reading a contemporary PHP web application, the code repeatedly addresses this user - the buffer overflow, URL-munging, SQL-injecting script kiddie who is not the core ethos of the feature set, but whom the code constantly addresses and implies in such a way that we who read the code come to know what this hacker is like (or is expected and believed to be like).
Reply by John Bell on February 14, 2010 at 9:35am
Jeremy, yes, I think that adding in implied programmers/users helps clarify what I was getting after with adding an ideal user to the code creation system. To go a bit further down the rabbit hole:
I was thinking of the execution part of the ideal user not as a role where someone fulfills the stated purpose of a piece of software, but as a role where all uses of a piece of software are carried out. More specifically, the ideal user is responsible for defining what the functionality of a piece of software should be and determining how well it meets that goal. As part of that evaluation the ideal user discovers not only where the software meets or falls short of the functional goal, but also where it exceeds it and does something unexpected. The DUI lawyer is evaluating the code against a functional standard regardless of whether or not he or she ever tries to execute it.
Under that definition the hacker reading for exploits is still within the ideal user space because they are using the software’s functionality (or lack thereof) against it. For me an interesting question here is whether or not the ideal programmer is aware of and responsible for all the possible uses of the code they create. The tension in the system is between the programmer, who knows everything the code should do, and the user, who knows everything the code actually does. While it’s tempting to say that an ideal programmer only writes code that does what is intended, I’m not sure that’s true; it’s the question of whether or not an ideal toolmaker only makes hammers that can’t be used to hit somebody in the head.
Back in the real, constructing implied users during a reading of code would seem to be a good way to get to the heart of that programmer/user tension. If there is code that implies a certain use, then clearly the programmer has anticipated it. If there is functionality that is not implied-good or bad-it is the result of a user going beyond the implied programmer’s vision. And of course, you pointed out several other (more) useful things an implied user can add to a reading of code as well as just probing this little theoretical model.
In the case of the CRU code, as you say, different readers will construct different implied programmers. My question was whether the difference between those programmers-deceitful vs. earnest-is a result of misattributing a user role to a programmer. For some, CRU is a black box that is both user and programmer (regardless of the individual people that make up CRU) and mixing the two results in code that was influenced by an agenda. For others, the programmer and the user are kept separate, and the programmer just had a bad day or left a few ambiguous comments. For readers who have constructed those implied programmers it may not be relevant as they’ve already built in those implications, it’s just in retrospect that I wonder about their origins.
Reply by Elizabeth Swanstrom (Lisa) on February 12, 2010 at 6:51pm
My challenge to the workshop for this week is to find concrete examples of actual code reading that enrich our idea of who reads code…I propose a dose of the real.
In response to Jeremy’s challenge, both to find a concrete example of “actual code” and bring “a dose of the real” to the discussion, I’m interested in code that feeds people. On Daniel Folkinshteyn’s web site, a link named “RiceMaker” will take the curious reader to a wiki page that describes how to install and run a piece of code on one’s computer. This piece of code is a specific type of webbot, one used to interact with the UN Worldfood Program’s FreeRice website. According to the author of the bot, “Ricemaker is a python script that automates the vocabulary game on FreeRice to generate rice donations. In other words, it is a FreeRice bot…if you run RiceMaker 24/7, and don’t change the loop delay settings from the default of [a] 3 second average, you can feed about…8.1 people per day” (http://wiki.df.dreamhosters.com/wiki/RiceMaker).
I very much appreciate Jeremy’s desire to move from how we “should” read code to how we “do” read code, and in the spirit of this ambition, I’ll offer up an issue that this work has raised for me. In addition to questions about the ethics of such a script (the FreeRice program has initiated an unambiguous “no bots” policy), one of the largest questions I have in looking at this code - and I hesitate to say “reading,” because my knowledge is so provisional - has to deal with the way I came to it, which is to say as embedded within other variously coded textual environments (on the web, on a wiki, in English, in a text editor, etc.). While reading these different layers is of course relevant to my specific project, my question here is scalable: given that it’s useful to read code both closely and contextually, i.e., within/against/among/over/under (pick your favorite preposition) other types of codes, what points of intersection have proven particularly fruitful?
Here is an excerpt from ricemaker.py:
`self.starttime = time.time() #our start time - will use this to figure out rice per second stats
try:
self.iterator = 0
while 1:
self.iterator += 1
try:
self.queueitem = self.queue.get(block=True, timeout=10)
self.ricecounter += int(self.queueitem[‘rice’])
print “iteration:”, self.iterator
print “thread number:”, self.queueitem[‘print’][‘threadnumber’]
print “targetword:”, self.queueitem[‘print’][‘targetword’]
print “answer:”, self.queueitem[‘print’][‘answer’]
print “correct?”, self.queueitem[‘print’][‘correct’]
print “vocab level:”, self.queueitem[‘print’][‘vocablevel’]
print “total rice this session:”, self.ricecounter
print “total rice all recorded sessions:”, self.running_rice_total + self.ricecounter
print “percent correct this session:”, str(round(self.ricecounter/self.answer_value/self.iterator100.0, 2))+”%“
print “iterations per second”, str(self.iterator/(time.time()-self.starttime)), ”;”, “rice per second”, str(self.ricecounter/(time.time() - self.starttime))
print ”*****************************************”`
Reply by Jeremy Douglass on February 14, 2010 at 12:34am
Lisa,
Thanks for this excellent example - I wasn’t familiar with RiceMaker and FreeRice. I have a number of reactions to this, some of which started with the narratives that get wrapped around the RiceMaker script (especially their section: “Ethical Considerations”) and the FreeRice webservice (e.g. the defense offered in “FreeRice a scam? Ask the beneficiaries”).
I’m not sure that I’m ready to say anything interesting about the code above yet that would go beyond what it says it does on the wrapper, but I have the beginning of an idea of how I would head into the code. Essentially, there are several competing descriptions of what “FreeRice” is. One is the actual set of financial arrangements backing the site. Another is the public description (or approximation) of these business processes as a proxy-donation arrangement (with its implicit dependency on ad-driven corporate volunteers). A third description is the actual software driving the FreeRice service (which makes this relationship automatic and procedural), and the way it gets wrapped in a web interface that moves the proxy-sponsor into the footer, and tells the user that they are literally creating grains of rice with each interaction. Finally, the RiceMaker code is a kind of “reductio ad absurdum” / “modest proposal” - it responds to the mild white lie of the web service by taking it completely seriously, as if an internet signal could (ex nihilo) “make” grains of rice.
So one way I might approach the RiceMaker source code is, how do the bot code procedures imagine the UN partner program, and how is this description mirrored / contested by other descriptions? I’m not sure if the code will be interesting or surprising yet, but I can already imagine other ways that might be interesting to approach it even if it is quite straightforward in structure - for example, if that straightforward structure id similar to other types of code (like CAPTCHA-cracking spam-bots, or evidence-pooling SETI@Home clients) that we don’t usually talk about in the same registers.
Reply by Evan Buswell on February 13, 2010 at 8:17pm
So, I’ve been thinking about the Climategate videos all week, and I finally figured out what’s been bugging me. I went to the website for the CRU’s temperature data sets and then skimmed through each of the published papers they listed there. The software is hardly even mentioned.
Reciprocal to this week’s question is the question: How is code not being read, where we might expect it to be read?
In the case of “Climategate,” I see in the scientific research this overwhelming assumption that the code is wholly secondary, that it is completely transparent insofar as any truth claims are concerned-though I don’t know much about the climate research discourse, so correct me if I’m wrong. For example, in the paper, “Uncertainty estimates in regional and global observed temperature changes,” the computer and its programmer do creep in under the headings “Homogenization Adjustment Error” and “Calculation and Reporting Error,” but the first error is treated as essentially equivalent to choosing correct mathematical adjustment models, and the second is treated as equivalent to correct calculation procedures on the part of the scientist. That is, as far as truth value is concerned, the design (architecture) of the computer program is assumed to be epistemologically equivalent to the use of the appropriate mathematical models, and the implementation of the computer program is assumed to be epistemologically equivalent to the hand calculations of the scientists.
Similarly, the pro-warming video ends by accusing the sceptics of “assuming far too much about the scientists.” Not to read too much into that statement, but even after a thoughtful analysis of the possible interpretations and contexts of the code, this video ends by emphasizing the value of what’s not code: the scientists, as people.
As I’ve wrote and deleted several poorly-thought-out versions of this next paragraph, I’ll just post it as a question. Here’s what I’m thinking about: is this emphasis on the scientists, this emphasis on what’s not code, just a symptom of a culture that hasn’t caught up with code’s existence yet? Or is there some vested interest-other than the obvious intellectual property interest-that wants the code to be hidden or ignored?
Reply by David Shepard on February 14, 2010 at 6:12pm
Is this emphasis on the scientists, this emphasis on what’s not code, just a symptom of a culture that hasn’t caught up with code’s existence yet? Or is there some vested interest-other than the obvious intellectual property interest-that wants the code to be hidden or ignored?
I really like this question. I think the under-emphasis on code is a symptom of a larger under-appreciation of, or lack of knowledge about, code. This is something I’m looking at in my dissertation: fictional computer programmers tend to be evil sociopaths (e.g. The Net, Virtuosity), freelancers who aren’t in charge of the schemes they implement (Swordfish, Live Free or Die Hard, Firewall), or Frankenstein-like scientists who get trapped in their own machines (Colussus: the Forbin Project, Terminator 2, Pi, and The Matrix). Technical knowledge rarely makes someone heroic. To me, this illustrates a hope that even as computers endow us with greater power, they don’t fundamentally change us because they only do what their programmers tell them. This trope is generally associated with formal simplicity: stories that are themselves straightforward Hollywood films or something we might write off as pulp fiction.
Some postmodern fiction exemplifies a counter-trope by mapping structuralist theories about language onto code: language is a closed system that helps to structure thought, so if our brains are cybernetic symbol-processing systems, they can be “reprogrammed” by reading the right sequences of words. Language and code affect or create the ideas that can be expressed. The difficulty of coding shows us that computers aren’t as powerful or easy to use as we would like, and that they shape human existence significantly so as to undercut the idea of a stable core to human experience. Some examples would be Burroughs’ novels (since Burroughs apparently thinks textual cut-ups can help “deprogram” readers by showing them possibilities they wouldn’t otherwise see) or Don DeLillo’s Ratner’s Star, about scientists creating a robot that speaks a programming language free from ambiguity.
The response to the CRU code seems to show us that we want to believe that the code could only show the intent of the scientists, even though it could deviate from this because of typos or language strictures unknown to the programmer. Computing seems to be a bastion of representationalism; even though we no longer trust the transparency of language, we want to believe in the transparency of code, perhaps because the specialized knowledge required to write it. David Porush puts forth the theory that cybernetics emerged to compensate for the uncertainty of quantum physics, and the same desire - that we can represent processes or objects transparently through computing if not through language or writing any more - persists in our understanding of code.
David Noble argues in Forces of Production that computerization doesn’t make workers more efficient (and he’s not alone). However, the perception of the CRU code as epistemologically equivalent to the scientists’ calculations suggests to me the persistence of the perception that computers can be transparent machines - that they can simplify tasks without necessarily altering the questions that can be asked.
Reply by Jeremy Douglass on February 15, 2010 at 12:35pm
Evan, very interesting observation on the presence or invisibility of code in the literature. If code is the complex set of contingency strategies where the messy business of science is being effected, then perhaps that mess is always effaced in the literature, which doesn’t enumerate the many exceptions thrown, or who (if anyone) will catch them.
As to emphasizing people, not code, I see how you can feel that the second “Debunking” video falls into this line of argument, and it may, although my sense was that this was not the author’s intention. On the one hand, the video creator constructs an implied programmer, and makes arguments about that programmer’s character and intention - and perhaps this is an over-engagement with the tar-baby of intentionality. Yet this discussion seems to me to be by the wayside of the debunker’s quite formalist stance, arguing that the code itself will tell us what it does. I see this formalism signaled early in the objection that critics are relying on an “ad hominem” fallacy: the programmer’s low opinion of his own work (which extends to logs, comments, etc.) is not proof that the work itself functions poorly. This is strikingly similar to a New Critical position like Wimsatt and Beardsley’s “intentional fallacy”, which dismisses the opinion of the author (and indeed almost banishes the person of the author entirely) as irrelevant distraction from a discussion of the work itself. Such moves are generally intended to focus attention on formal textual analysis.
Reply by José Carlos Silvestre on February 14, 2010 at 2:45pm
Technical evolution: What’s technical evolution here is sort of ill-defined. I like some theories of technical evolution - Leroi-Gourhan, and especially Simondon - but I find it non-trivial to apply them to software. Simondon speaks of a process of concretization: that the technical object starts as an “abstract” machine (with independent, single-function parts easily reducible to boxes and arrows on a black board) and then advances to a “concrete” form - in which all parts are interdependent and cannot be thought of in isolation (so, for example, a component of an engine that had a single function will also participate later, due to its placement and so forth, in heat dissipation: “In the modern engine, each critical piece is so connected with the rest by reciprocal exchanges of energy that it cannot be other than it is.”) According to Simondon, this is not a matter of economic pressures or some such, but a process intrinsic to technics (“It is not the production-line which produces standardization; rather it is intrinsic standardization which makes the production line possible.”) At the same time that the concrete machine is fully integrated, Simondon also argues that its perfection lies on “concealed margins of indetermination” and its capacity to adapt to and engage with the environment: not “function by function,” but “synergy by synergy.”
So, as the assembly line is concrete and the artisan’s work is abstract, we could think that the organization of OOP is more concrete in that everything has to be in its right place and this plays a certain role, whereas in a language like PHP the single elements can be connected arbitrarily. Also, high-level languages produce machine code (which is the closest to a “technical object” here) that is optimized in its arrangement and thus more “concrete.” But then there are the margins of indetermination and, as it was pointed out, OOP did not interact very well with the demands of the environment that is the web. I am trying to put the points that were made here regarding technical evolution in the terms we might inherit from the philosophy of technics.
Reply by Jeff Nyhoff on February 14, 2010 at 4:36pm
Implicit in the question “Who reads code?” there is also the question: “Who doesn’t/shouldn’t/mustn’t read code?”
In the pre-GUI era of personal computing, the “user” identity was one that allowed for a user to at least be aware of code, perhaps also examine and read code, perhaps also modify code, perhaps also compose original code.
However, since 1984, the “user” identity was re-manufactured and installed as the “end user” - who, by definition, doesn’t/shouldn’t/mustn’t read (let alone write) code.
Accordingly, I would suggest also that “code” has become, first and foremost, “something that the end user doesn’t/shouldn’t/mustn’t see.”
Indeed, I think it might be said that “code” has come to be “ANYTHING that the end user doesn’t/shouldn’t/mustn’t see.”
Can any conception of “code” in this era responsibly sidestep this implicit “hiddenness” - and, more specifically, the “hidden-from-end-users-ness” of code, which constrains and interpellates the end user to the performance of the role of “ideal non-reader” of code?
Reply by Micha Cárdenas / Azdel Slade on February 15, 2010 at 8:35pm
Jeremy, I love your intervention about moving from two types of readers to a multiplicity of readers. It’s a fundamental part of queer theory, rejecting binary thinking, and it’s been a major part of my own work, to explore ways of developing new genders outside of make and female. I also tried to do this a bit last week, but thanks for bringing some more focus to it. Of course, we could also see a lot of post-structuralism, like Deleuze and Guattari’s rejection of teleology (we’re tired of trees!) as a way of moving away from a system of thought based on two endpoints and towards a rhizomatic system branching out in all directions.
But to join in on the project of finding code snippets and code readers that broaden our notions of who’s reading code, I have two examples.
The first one is in the Second Life Viewer’s open source project’s bug database. The important part of this snippet and the long discussion surrounding it is the requested function, LLGetGender, and the many fears this proposed function created among the many different users of Second Life, including repercussions for social structure, sexual interactions and economic impacts.
The second example I want to share is these two images:

which show our pure data patch projected onto our bodies before our performances. Its interesting because before almost every single of our performances of technésexual, we’ve ended up showing the patch onscreen because we’re trying to get all the parts of the technology to talk to each other. Many times people ask us if it’s part of the performance or say that they felt like it was part of the performance. So, that opens up a larger audience of people seeing our code and discussing it with us as well.
Reply by Andrew Davis on February 23, 2010 at 4:48pm
We take quotes out of context in literature when they represent valuable complete thoughts.
Why isn’t code the same way? There are certainly well-known cases where the context is irrelevant to understanding the complete thought and value of that thought in a snippet of code. Search for ‘Duff’s Device’ or go directly to http://en.wikipedia.org/wiki/Duff%27s_devicehttp://en.wikipedia.org/wiki/Duff%27s_device.
It was profound not only because of its innate value in solving one particular problem, but because it is the equivalent of a Japanese Koan to a professional programmer. It shocks the programmer so thoroughly they must re-evaluate their understanding of the language it is implemented in. In fact it was so shocking a juxtaposition of different constructs that several compilers failed to compile it correctly. It was later added to the test suite of C standards for compliance.
Here is an entire collection of similar ‘valuable’ snippets of code without context http://graphics.stanford.edu/~seander/bithacks.html. Specifically look for “Counting bits set, in parallel.”
Every programmer I know learns new things when reading these code snippets. The sudden change from ‘writing code’ to ‘crafting code’ occurs as they search out ways to apply the new knowledge…or craft their own to share.
Surely the art or craft of a Koan is not limited to literature. Are there other forms or structural dialects that repeat à la iambic pentameter, sure. How does one search for the form of code, rather than the substance of it?
Reply by Jeremy Douglass on March 11, 2010 at 11:21am
Andrew, you ask some challenging questions - and point towards some interesting debates.
Earlier, you mentioned Joel Spolsky’s “The Law of Leaky Abstractions.” That essay argues that there is an increasing need / obligation / burden for the programmer to understand higher level languages in terms of how the lower layers actual work - I might paraphrase it as a strong form of the agurment that code understanding has to happen in context, and that context goes all the way down (to TCP/IP, the file system, the hard disk platter). Of course, Spolsky doesn’t say you always need to use this understanding, just that context is crucial at the moments when things “leak.”
Likewise, your example of Duff’s device was (for me) embedded in some very particular contexts - how certain processes are traditionally handled in assembly, of how they can be optimized for speed in the context of specific hardware / software performance costs, and how some surprising and for many unforeseen consequences of the C language specification can address this. I wasn’t familiar with loop unwinding / loop-unrolling, but even once I understood that I’m not completely confident I understand that crazy case block.
I’m a big believer in contextual reading and in the power of excerpt and abstraction - that’s why I’m interested in whether these things are opposites or complements. Sometimes I’ve actually seen the argument for clear lucid code excerpts presented as a kind of “against code koans” counterargument. For example, in “Aiming for Cartoon Code First,” Russell Miles proposes such an opposition - code-as-art is dense, opaque, challenging, rewarding, but most of all just hard to understand. “Cartoon Code,” on the other hand, is light, transparent, and easy to understand - although Joel Spolsky might retort that this ease only lasts until the simplicity “leaks.”
What I’m trying to get a handle on is the difference between quotation / excerpting as “out of context” (I felt I needed a lot of context to understand Duff’s device) and the more general question you suggest at the end: “How does one search for the form of code, rather than the substance of it?” Is this form an excerpt, or an abstraction, or something else? When I read this question, my first association is with “pattern,” specifically as used in books and essays I’ve read on design patterns. This may be a higher level of abstraction than you were thinking of, but that is my first stab at the search for form: one design pattern is like a description of the haiku form, while a particular snippet is like an individual haiku (if it has a form - it may be free verse).
Reply by Andrew Davis on March 11, 2010 at 3:16pm
The competition of in/out of context viewing models is false. When I sawI want to distinguish the word ‘see’ or saw from ‘read’ in this case. This goes to my second point about code ‘form’. There are many forms. The one I talk about here is the landscape form on a page. Certainly a viewer can take in code by reading it. They could also shrink the font down to pixel size so that the words are unintelligible and then see one variant of the code form…a landscape if you will. In this form, a switch statement is very visible. So I read Duff’s device as a switch statement. But then, on reading it, I see Duff’s device as a loop with multiple entry points (8 in the example case). This is where the snippet of code becomes a story in its own right. A switch changing to a loop, the intrigue, the suspense, the revelation. But then, with context, perhaps resolution. So does critical reading include this landscape form viewing? I can liken it to reading a table of contents to understand the flow before the first word in a chapter is started. Duff’s Device is almost like having a table of contents that lies about the actual story flow. Duff’s device for the first time I had probably already authored 100k LOC and read 1M. So for me, the initial non-sensical syntax of it was a shock to the system. Then, perhaps after understanding the code flow through the loop, and it is most definitely a loop first, you start to ask questions about why this was needed. But the power of this syntax was, in my experience, the thing that started my thinking about how code is a language and about expression as much as it is a set of instructions for a computer to execute.
Cite this essay
Douglass, Jeremy. "Critical Code Studies Conference - Week Two Discussion" electronic book review, 14 April 2011, https://electronicbookreview.com/publications/critical-code-studies-conference-week-two-discussion/