Data-Realism: Reading and Writing Datafied Text

Pold and Erslev explore third-wave electronic literature -- a practice situated in ¨social media networks, apps, mobile and touchscreen devices, and Web API services” (Flores). At the next conceptual level, however, literary practices of this kind unavoidably take part in representing and reconstructing the metainterface - a space of data collection, standardization, commodification and redistribution that, for better or worse, is our context for a contemporary data realism.
Introduction
As argued by Leonardo Flores, we see the emergence of Third Generation Electronic Literature which “uses established platforms with massive user bases, such as social media networks, apps, mobile and touchscreen devices, and Web API services” (Flores). However, as pointed out in Kathi Berens’ discussion of Instagram poetry, reading only the immediately visible text will not give comprehensive insight into the ways third generation textuality “is inextricably co-constituted with (…) metadata” and “engaging its literary and artistic meaning comes at the cost of shedding behavioral data that is collected, collated, and auctioned.” The platform and its datafication of reader response becomes an essential part of the text, described by Berens as a “new kind of ‘reader response,’ where algorithms are agentic: the human reader is herself ‘read’ by behavioral targeting algorithms, parsed for commercial susceptibility, and served new information or ads designed to entice transaction, even if that transaction is only a click.” (Berens 2019a). Faced with such agentic (and often hidden) behavioral targeting algorithms, the question we pose is how we can read this textual phenomenon, that is to say, which kind of realism do we need in order to read the text’s data, or the data’s text?
As Berens also points to, Third Generation or Post-Web e-lit takes place in platforms that can be characterized as metainterfaces (Berens 2019b). Metainterfaces are both omnipresent and invisible, they map traffic and people, but perhaps their most intricate and directly felt experience is how they are related to - and control - literacy, reading and writing (Andersen and Pold). All this is of course highly relevant for electronic literature and should be explored critically in relation to third-gen./post-web/metainterface e-literature. In short, measuring and modeling affective relations becomes a central business model of a cultural metainterface industry. In fact even our scholarly critical readings are encased in these platforms, when we criticize social media on social media or metainterfaces in a Google Doc, in the way that all our online and digital reading and writing behavior is registered by the metainterface industries and thereby are adding data to its bases, while it is difficult or often in actual practice impossible to get access to the layers and complexities of the platform (e.g. the tracking mechanisms, the data, the layers of code, the networked complexity of exchange and the business model).
The so-called third generation e-lit is here viewed as a practice of writing with(in) the metainterface. Our approach is to focus on a realism of the role of data-driven software in contemporary writing and reading practices. The term which is coined here, data-realism, does not refer to a question of whether data is realistic (paraphrase of ‘close-to-reality’), or whether specific data-driven techniques such as machine learning are realistic ways of processing data (paraphrase of ‘close-to-human-cognition’), but rather how third-wave e-lit takes part both in representing and reconstructing the metainterface. Here, third generation e-lit is part of the metainterfaces in question, thus it also explores their “tendency” and points to alternatives (Benjamin). It writes with both the text and the metainterface; its data, material and code. Even if the data-realist third generation e-lit works highlighted here do not directly engage with what is typically called the ‘material’ of computational systems (i.e. the code), they take part in constructing and reconstructing the culturally shared imaginaries related to these systems, which are here considered to be equally ‘materialist’ as e.g. the code (Bucher).
Often metainterfaces appear to be ‘smart’ and hide their functionality behind seemingly banal functionalities in order to be integrated ‘seamlessly’ into reality, but they also come with grammars-of-action (Agre). These grammars-of-action are at least in part constituted by our imaginaries surrounding the system in question, and gradually become visible and readable as exemplars of a style with a specific rhetoric. With this paper we aim to discuss three different cases of e-lit that explore different aspects of data-realism and how to read the writing of data-driven software such as machine learning. Though we in part focus on machine learning, our focus is limited to what could be described as basic machine learning which is applications that do not include so-called ‘deep learning’ or neural networks (apart from what we might imagine runs behind Google’s AdWords platform).
Erica Scourti’s THINK YOU KNOW ME
Erica Scourti’s performative work THINK YOU KNOW ME (Scourti) is a live performance of texting habits, as expressed in a rambling reading/writing surge, intermixed with a set of pre-defined sequences of surprising poetic and semantic clarity, activated when Scourti uses specific texting shortcuts (e.g. double-t becomes “love is not the absence of fear”). The format for the performance (writing with predictive keyboards) has been around for at least ten years, since Apple started incorporating predictive text in their iPhones. Predictive text in general, especially the advent of markov chains, is of course also a well-known format in the e-lit community. Scourti’s performance adds the layer of pre-written statements to both trouble and rearticulate the predictive text paradigm.
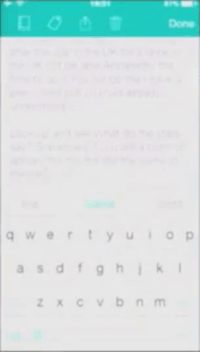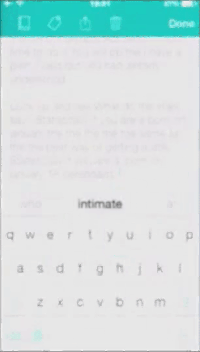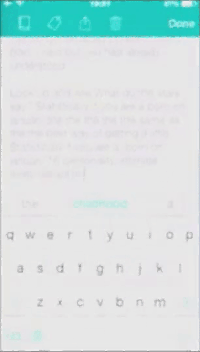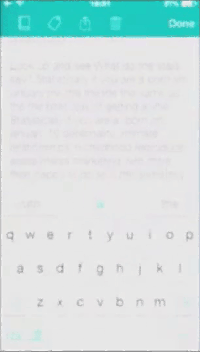
Gif created by the authors and reproduced with the permission of the artist.
The performance is at one level a realist expression of Scourti’s actual texting habits - or at least it is an expression of how these texting habits are picked up and statistically ordered by the iPhone. This is not the whole story though, as Scourti smuggles in pre-written, repeated statements which interrupt (or maybe actually inform) the otherwise chaotic outcome from the iPhone’s algorithmic attempts to predict Scourti’s next words. The title of the work, THINK YOU KNOW ME, is here echoed when Scourti repeatedly incorporates these statements which are nowhere to be found in the predicted/suggested text, troubling the idea of the system ‘knowing’ Scourti at all - the Erica Scourti known by the system does not, apparently, write poetically. Instead, it seems the Scourti known by the iPhone is mostly concerned with getting people to visit the website http://ericascourti.com. When Scourti intermixes the pre-written statements like “love is not the absence of fear” with the predicted suggestions to ask people to check out http://ericascourti.com for further info, the seemingly mundane activity of online networking suddenly envelopes a poetic reflection which seems to reference common dilemmas like the question of work-life balance and the tendency for artists to inscribe their lives and identities into their artistic practices. Who is Scourti texting? A friend? A potential curator? The audience? Herself? Does it matter? Not to the iPhone, at least.
The performance brings into question the role of text-based support technology and our relation to such technology in our everyday lives and in this way, it raises questions related to data-realism: The proposed language is often cyclical and becomes a kind of statistical average of Scourti’s texting habits. The pre-written statements disrupt the effectiveness of the algorithm, but they also inform it: Going forward, these statements will likely become part of Scourti’s iPhone’s predictive text database, and may appear in a future word suggestion. Would that, then, increase the poetic value of the predictive text algorithm, or decrease the poetic value of those pre-written statements? In the following, we turn to a critical investigation of the value (both poetic and monetary) of words, as viewed by the Google AdWords platform.
Pip Thornton’s {poem}.py
Whereas Scourti explores how the basic machine learning of the predictive keyboard interferes or co-writes with her writing, artist-researcher Pip Thornton creates, with {poem}.py (Thornton 2017), a critical intervention in the way that Google controls language through the linguistic capitalism of its AdWords platform. Thornton’s tactic has been one of “purposefully making” a “critical stance from within the master’s house” or “algorithming the algorithm” (Thornton 2018, 418). The AdWords platform is Google’s remuneration platform which allows Google to auction search words to the highest bidder. Thornton can - as any potential advertiser - get access to suggested bid prices through Google’s keyword planner, which is a tool that advertisers can use to plan their budget and bid prices. {poem}.py is created as a Python script to take any text, run it through the keyword planner and generate a receipt with the price of all words listed in order and their price calculated from the keyword planner. Thornton mainly uses literary text and poetry as a way to reverse “the performative logic of language by reclaiming poetry from the algorithmic marketplace, repoliticizing it, and turning it back into art” (Thornton 2018, 432).

Gif created by the authors and reproduced with the permission of the artist.
As Thornton points out, {poem}.py demonstrates a discursive economy within contemporary linguistic capitalism through its intervention. Google’s proprietary algorithms are still hidden, Thornton manages through {poem}.py to “see (and show) what goes into the search portal, and what comes out the other side” (Thornton 2018, 432). In this sense the work is an example of data-realism that shows, not the machine learning behind Google’s interface to which we have no access, but how it performs through its valuation of words and language. One of the aspects highlighted by Thornton (which also would not be observable in the code but only in its performance) is that words such as “cloud” or “host” in one of the inputted poems, Wordsworth’s “Daffodils”, are peculiarly expensive, not because of their literal meaning in language or poetic meaning in the poem, but because of their value as words in computing (as in cloud computing and website hosting). Words in this system tend to lose their richness and multiplicity of meaning, not to say their poetic dimensions, to the benefit of the singular most valuable meaning as AdWords, a standardization dynamic also seen in search engine optimization: in short, the workings of the discursive economy. In this and other cases the intentional context is also lost to the arbitrary auctioning of the market, as “cloud” is attracted by the vectors of computing and distanced to the nature that Wordsworth writes about, even though cloud computing and Google was beyond the imaginative for him. If “cloud” started as a metaphor for specific kinds networked computing and storage, {poem}.py demonstrates how computing overruns the metaphor and takes over “cloud” as simply a description of computing. It is as Thornton argues “a form of algorithmic governance, or a technologically facilitated version of the classic literary intentional fallacy,” echoing Orwell’s Newspeak from Nineteen eighty-four, a language designed to be “impossible to use for literary purposes” (Thornton 2018, 429, 430).
Thornton points to and demonstrates a serious criticism of what Google and AdWords does to our language, that we should not take lightly. We would do better to discuss the conditions of Google’s linguistic capitalism in continuation of similar observations made by Cabell and Huff or Christophe Bruno (Thornton 2018, 424-425). However, as Thornton also notes, language has never been independent but has always been marketable and according to Walter J. Ong, already the printing press “embedded the word itself deeply in the manufacturing process and made it into a kind of commodity” (Ong 116) and literature as a modern art form is intimately integrated with the discursive economy. Furthermore, {poem}.py as a work of electronic literature demonstrates a good way to use linguistic capitalism for literary purposes, which can be characterized as data-realism. It demonstrates how language is not innocent, but part of a production process, in fact it even allows us to see the performance of this linguistic machine in new ways. Contemporary language, including its data processing and economy, is shown as a black box, whose performance has become readable, and Thornton shows how we are able to speak - if not freely then at least with growing awareness of the algorithmic intentional fallacies. Interestingly, classical realism explored similar dynamics between capitalism and literature. As Georg Lukács pointed out, already Balzac wrote novels about how literature became commodified in a capitalist production system, and how this led to a capitalization of ideology (Lukács). As a work of data-realism, {poem}.py lets us read the datafied language through a critical engagement with its algorithmic commodification as a conscious exploration of a new algorithmic discourse economy.
@KeatonPatti’s Olive Garden Tweet
So far, we have investigated two exemplary artworks which make use of a kind of datafied word management, and related these to what we call data-realism. In the following, we turn to an investigation of how this data-realism also exhibits an emerging style, which is both recognizable and re-mixable.
In a series of popular tweets, Keaton Patti has from the Twitter profile @KeatonPatti explored the style of text-generation algorithms (in the form of bots) by writing in a bot-esque style 1. These tweets take the form of screenplays, and are accompanied by the claim that @KeatonPatti “forced a bot to watch over 1,000 hours of” some kind of pop-cultural content, then “asked it to write” similar content (cf. Patti). We focus on the to-date most viral one, the “_Olive Garden Tweet” (Patti). We consider the style at play as a kind of bot-mimicry, since no actual bot is part of the writing process; the alleged ‘outputs’ of this style of writing are consciously written to perform in a stylistically similar way to auto-generated text. Interestingly, the readers on Twitter are generally quick to recognize the style as bot-esque, but they are also quick to see through @KeatonPatti’s lack of an actual bot, and realize that the text was written by a human. We read @KeatonPatti’s way of leveraging a bot-esque style as part of a complex meta-parody - one not only parodying various pop-culture phenomena, but also (maybe even more-so) parodying the proliferation and fascination of bots in the online landscape. They are a way of coping with the rapid and seemingly all-encompassing changes happening to the way we perceive, interact with, and conceptualize text brought about by the metainterface.

Found on Twitter (Patti).

Found on Twitter (Patti).
In order to thoroughly understand the bot-mimicry phenomenon at play, one must read the alleged outputs as though they were generated by an automatic writing agent, and thus to seek insight into the imagined generative process. Indeed, in order to read and understand the bot-esque style, @KeatonPatti and the reader(s) alike must, implicitly or explicitly, rely on a conception of what bots in general are and should be. In a previous study of @KeatonPatti’s bot-mimicry, it was found that the bot seems to be both a harmless generator of nonsense and at the same time possessing almost mystical abilities to extract a kind of cultural essence from the inputted data (Erslev). This dual conception of bots makes way for a machine learning rhetoric which legitimizes outputs from machine learning systems as being both controllable and at the same time magically accurate beyond our comprehension. These outputs are often presented as an essence of the corresponding input, and due to the common idea that machine learning systems are opaque, the output is often validated without scrutiny. @KeatonPatti leverages the emerging machine learning rhetoric, making these tweets bridge the divide between random shitposting and potent parody. At the same time, @KeatonPatti’s tweets present a unique opportunity to scrutinize the way that machine learning systems are presented, and the accompanying imaginaries, which maps on to our examination of data-realism.
Here, it is interesting to consider how @KeatonPatti’s bot-esque style is in many ways informed by an understanding of how text-generation works, while the imagined bot shamelessly crosses the boundaries of what can be achieved with contemporary text-generation technology. The emerging style is not bound by advancements in natural language processing, but is itself a techno-cultural construct which examines the intricate ways in which machine learning software operates, while at the same time being a creative way of coping with the fear of unrecognizable bots passing as humans online. @KeatonPatti’s tweets (in particular their popularity) also make evident that bots leave a trace in the form of a specific data-realist style. While the style in question often takes form as humorous babbling, the style is, arguably, also a form of convincing rhetoric: things written in bot-esque style do tend to be perceived as an accurate essence of whatever was inputted into the system.
The Oracle from Selphie
“The Oracle from Selphie” (Woetmann et al.), the newest version of The Poetry Machine/Ink After Print (Fritsch et al.) more or less emerges from these considerations, and brings them together in a new form. It was developed by the authors in collaboration with Jakob Fredslund and CAVI, Aarhus University (Halskov). “The Oracle from Selphie” is both research-through-design and at the same an exemplar of data-realism. It includes an intro-text which introduces its concept in marketing-style language, hinting that The Oracle uses machine learning systems to generate accurate horoscopes. The important thing here is that, like @KeatonPatti’s tweets, The Oracle is in no way based on machine learning. Instead, The Oracle harnesses the machine learning rhetoric explored above; if and when the reader recognizes a hint of machine learning in the style of the horoscopes, the machine learning rhetoric is actualized and the work becomes data-realist.

Our approach has been to re-design the established interface of The Poetry Machine to make it re-embody some of the considerations originally intended for it – i.e., the questions of creativity and authorship; who is writing whom when we interact with the computer; what do we gather about a system when being met by a user unfriendly interface, etc - while at the same time incorporating new and peripheric perspectives such as the question of data-driven software and machine learning and, in particular, how we conceptualize such data-driven software and machine learning in the meeting with interfaces that hint at an artificially intelligent system. “The Oracle from Selphie” echoes the question of who is writing whom that Scourti’s work takes up, while adding the discursive economy brought up by Thornton through its play on social media interfaces like Facebook, including its metrics, affective economy and editing. All this takes place in a context where machine learning is referenced as a style without being present, as is the case for @KeatonPatti’s tweeting style, but this time the text, style, and interface is open for reading and writing by interacting users considering whether their horoscope and destiny is written by them or the machine. In this sense The Oracle concludes - or foretells? - this initial literary exploration of data-realism.
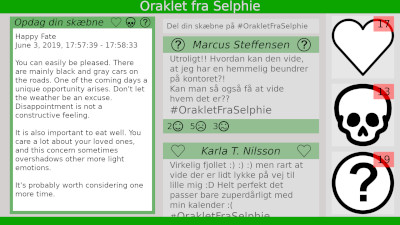
Screenshot taken by the authors.
Acknowledgements
Thanks to CAVI, Aarhus University for the continual support and co-development of The Poetry Machine.
Works Cited
Agre, Philip E. “Surveillance and Capture: Two Models of Privacy.“ The New Media Reader, edited by Noah Wardrip-Fruin & Nick Montfort, The MIT Press, 2003, pp. 737-760.
Andersen, Christian Ulrik and Søren Pold. The Metainterface: The Art of Platforms, Cities and Clouds. MIT Press, 2018.
Benjamin, Walter. “The Author as Producer.“ Selected Writings, edited by Michael William Jennings et al., vol. 2, Belknap Press of Harvard University Press, 1996, pp. 768-782.
Berens, Kathi Inman. “E-Literature’s #1 Hit: Is Instagram Poetry E-Literature?“ Electronic Book Review, vol. 2019 a, no. 04-07, 2019a, http://electronicbookreview.com/essay/e-lits-1-hit-is-instagram-poetry-e-literature/.
---. “Third Generation Electronic Literature and Artisanal Interfaces: Resistance in the Materials.“ ebr [electronic book review], vol. 2019 b, no. 5 May, 2019b, http://electronicbookreview.com/essay/third-generation-electronic-literature-and-artisanal-interfaces-resistance-in-the-materials/.
Bucher, Taina.. “The algorithmic imaginary: exploring the ordinary affects of Facebook algorithms.“ Information, Communication & Society vol. 20, no. 1, 2017, pp. 30-44.
Erslev, Malthe Stavning. “I Forced a Bot to Read over 1,000 Papers from Open Access Journals and Then Asked It to Write a Paper of Its Own. Here Is the Result. Or, a Quasi-Materialist Approach to Bot-Mimicry“ APRJA, vol. 8, no. 1, 2019, pp. 114-126, https://tidsskrift.dk/APRJA/article/view/115419.
Flores, Leonardo. “Third Generation Electronic Literature.“ Electronic Book Review, vol. 2019, no. 04-07, 2019, http://electronicbookreview.com/essay/third-generation-electronic-literature/.
Fritsch, Jonas et al. “Ink: Designing for Performative Literary Interactions.“ Personal and Ubiquitous Computing, vol. 18, no. 7, 2014, pp. 1551-1565, doi:10.1007/s00779-014-0767-2, http://dx.doi.org/10.1007/s00779-014-0767-2.
Halskov, Kim. “Cavi: An Interaction Design Research Lab.“ interactions, vol. 18, no. 4, 2011, pp. 92-95, doi:10.1145/1978822.1978841,
Lukács, Georg. “II Verlorene Illusionen.“ Georg Lukács Werke 6 - Probleme Des Realismus III - Der Historische Roman, Luchterhand, 1965, pp. 474-489.
Ong, Walter J. Orality and Literacy. Routledge, 1988.
Patti, Keaton. “Olive Garden Tweet.“ https://twitter.com/keatonpatti/status/1006961202998726665.
Scourti, Erica. “Think You Know Me.“ Transmediale, 2015. http://www.ericascourti.com/
Thornton, Pip. “A Critique of Linguistic Capitalism: Provocation/Intervention.“ GeoHumanities, vol. 4, no. 2, 2018, pp. 417-437, doi:10.1080/2373566X.2018.1486724, https://doi.org/10.1080/2373566X.2018.1486724.
---. “{Poem}.Py“ 2017. https://www.designinformatics.org/person/pip-thornton/.
Woetmann, Peter-Clement et al. “Oraklet Fra Selphie - the Poetry Machine.“ CAVI & Roskilde Libraries, 2019, 2012-. http://www.inkafterprint.dk/?page_id=45.
Footnotes
-
Taking the context of the metainterface platform Twitter into account, in particular the at times precarious relation between a person’s proper name and the profiles from which they post, we will use the Twitter anchor “@KeatonPatti” rather than the proper name “Keaton Patti” to refer to the publisher of the tweets here explored. ↩
Cite this article
Erslev, Malthe Stavning and Søren Pold. "Data-Realism: Reading and Writing Datafied Text" electronic book review, 3 May 2020, https://doi.org/10.7273/n381-mk15